Summary
Federated learning is an approach to machine learning that keeps sensitive data decentralized and local to the source. Having a unified data platform that can support it will be critical.


In an era where data privacy concerns are at the forefront, federated learning has emerged as a promising solution. Traditional machine learning models require massive amounts of centralized data for training, but that comes at a price—primarily in terms of data privacy and security. Federated learning, on the other hand, offers a way to train machine learning models without the need for centralized data collection.
Federated learning keeps sensitive data decentralized and local to the source. But as this approach gains traction, the conversation around its implications for data storage and privacy could get more complex.
What Is Federated Learning?
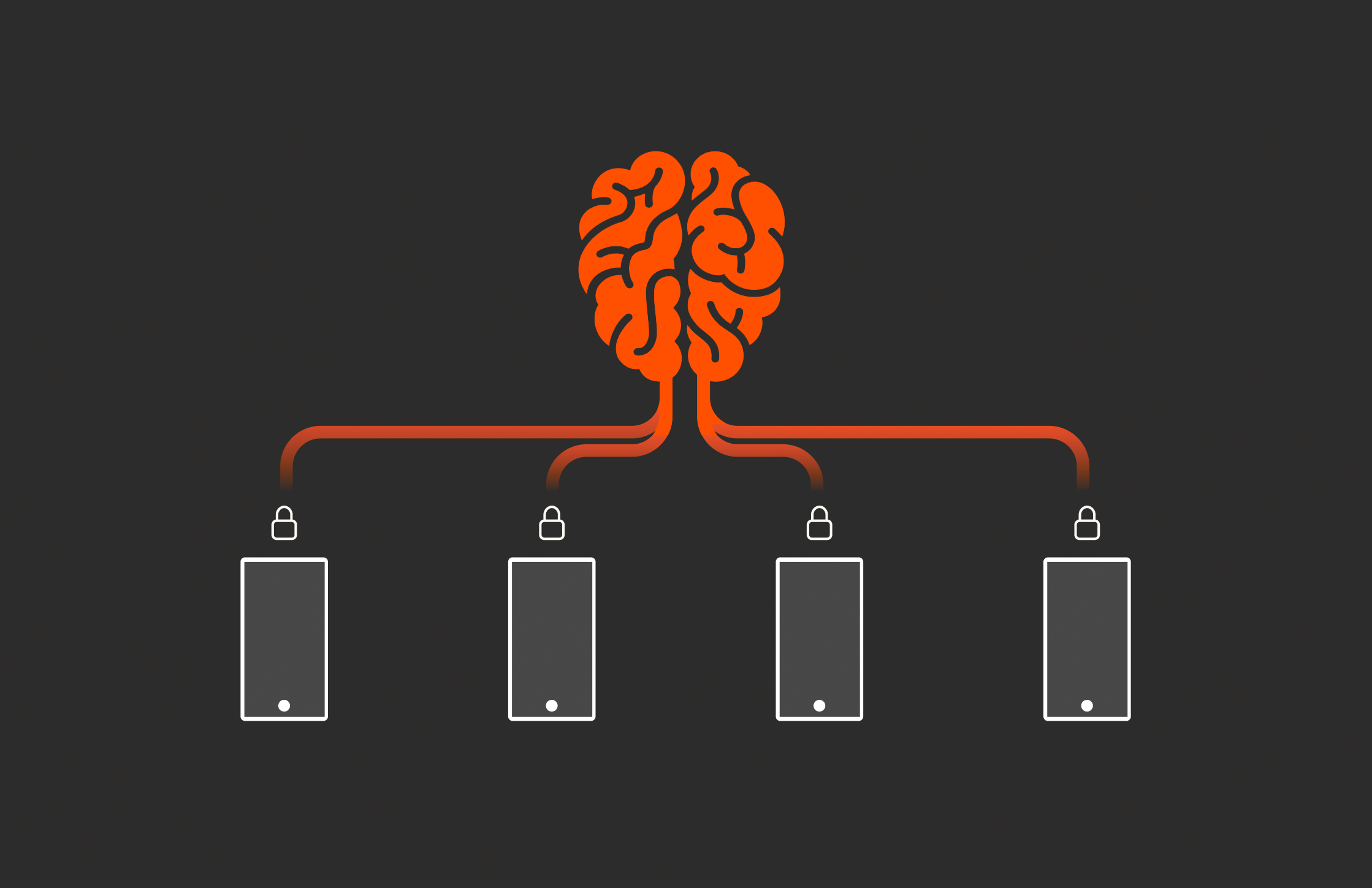
Federated learning is a distributed approach to machine learning where the model is trained across multiple decentralized devices or servers that hold their own local data. Instead of sending raw data to a central server for training, the process happens locally on each device. The local models are then aggregated at a central location, allowing the global model to improve without ever accessing the raw data itself. This method reduces data transmission and enhances privacy by keeping sensitive information close to the source.
Companies like Google have been early adopters of federated learning for applications like mobile keyboard predictions. Instead of sending user data back to the cloud, the learning happens directly on devices, which only share updates to the model, not the data itself. This framework inherently reduces the risk of data breaches because the raw data never leaves the user’s device.
Advanced Concepts in Federated Learning
Federated learning is not without its challenges. As the technology evolves, advanced concepts have emerged to address both its limitations and its expanding use cases.
- Federated averaging. This is one of the more nuanced aspects of federated learning. In this method, updates from local devices are aggregated in a way that ensures the global model improves without directly sharing or exposing individual data sets. This can be thought of as “learning by consensus,” where the central server only sees the model improvements, not the data itself.
- Federated multitask learning. This is another advanced approach. In many cases, different devices might have different kinds of data or may not all require the same model updates. Multitask federated learning allows for more flexibility by tailoring model updates to the specific tasks or data each device has while still allowing a form of global learning to take place. This is especially useful in settings like healthcare, where different hospitals might be using federated learning but focusing on different types of patient data, from MRI scans to genomic sequences.
- Differential privacy. As the landscape of federated learning continues to evolve, the concept of differential privacy has also become increasingly integrated into the process. Differential privacy adds a layer of mathematical guarantees to the data aggregation process, ensuring that the contribution of any single user or device to the global model remains obscured. This means that even if an adversary were to gain access to the aggregated model, they would be unable to extract meaningful information about individual users.
The Implications for Data Storage
Federated learning fundamentally shifts how we think about data storage and movement. In a traditional centralized model, massive amounts of data need to be transferred and stored in data centers for training purposes. Federated learning flips this model on its head, keeping data local to the source.
This approach significantly reduces the storage burden on central servers, but it also introduces new complexities for local data management. Since data is no longer moved to a centralized location, storage solutions need to be robust enough to handle decentralized data. Devices or edge servers need to have enough local storage to support the learning process, which could strain resources depending on the model size and data volumes.
Moreover, federated learning requires advanced synchronization between devices. Models need to be updated and aggregated in a coordinated way, without overwhelming bandwidth or storage resources on the local side. This introduces a new challenge for infrastructure, where storage solutions must be optimized for high performance and low latency, allowing federated updates to occur efficiently across distributed systems.
Another major shift is the storage lifecycle management. In traditional systems, data is archived, replicated, and backed up in centralized locations. With federated learning, the lifecycle of data becomes more fragmented. Local devices might be handling sensitive data that only remains useful for a short period of time, making efficient, decentralized data retention policies more important than ever.
Privacy Considerations
While federated learning is celebrated for its privacy advantages, it’s important to recognize that the model still presents challenges. Although raw data remains local, the updates sent to the central server can still leak information if not properly protected. This is where techniques like differential privacy and secure aggregation come into play. These methods ensure that even the updates themselves are obscured, preventing any accidental leakage of sensitive information.
There’s also the issue of data sovereignty. In a global context, federated learning respects local data privacy laws since data never crosses borders. This makes it a valuable tool for multinational organizations navigating complex regulatory landscapes like the GDPR in Europe or HIPAA in the United States. However, this also introduces the challenge of ensuring that data storage and model updates comply with each region’s regulations.
Learn more: What Orgs Need to Know about the EU AI Data Act
Federated learning also necessitates new governance models for data ownership. Since the data remains decentralized, organizations need to establish clear protocols for who controls the data, how it can be used, and how updates to the model are shared.
The Future of Federated Models: Unified Data Platforms
As federated learning continues to grow, data storage technologies will need to adapt to support this more decentralized approach. Storage solutions designed for the edge will become critical, as well as secure, low-latency networking to facilitate seamless model aggregation.
For organizations embracing federated learning, the focus should be on storage platforms that support decentralized data, secure aggregation, and compliance with complex privacy regulations. In a world where data privacy is increasingly paramount, federated learning offers a glimpse of the future—one where learning happens everywhere, but sensitive data stays exactly where it belongs.

ANALYST REPORT,
Top Storage Recommendations
to Support Generative AI
Be Future-ready
Support your initiatives with a unified data platform.
![]()