


This article originally appeared on Medium.com. It has been republished with permission from the author.
Part one of this post focused on how to configure Spark and FlashBlade® to use either NFS or S3. Part two demonstrates automation of a data science workspace and workload examples. Code can be found in the accompanying GitHub repository.
Automating Spark Clusters
Automating infrastructure tasks is essential to make data scientists more productive. Instead of working with data engineers to create clusters and set up the necessary tools, a data scientist can explore data and get initial results, productionizing only after the first results.
This means setup, configuration, monitoring, and scaling should be automatic!
The following scripts demonstrate various ways to automate: REST API, Docker volume plugin, Docker, and Bash.
Script 1: Creating S3 Credentials and Buckets Using the FlashBlade REST API
https://github.com/joshuarobinson/spark_docker_flashblade/blob/master/config_s3.py
This first script uses the FlashBlade REST API to automate the creation of an S3 workspace by creating an S3 account, user, access keys, and a bucket in a Python script. The output of the script is a credential file to store that S3 access and secret key so that they can be loaded into environment variables.
- The REST API enables services and automation to be built to simplify common workflows, e.g., provisioning workspaces, with either NFS or S3.
- Simple scripts act as glue between FlashBlade and other management or monitoring tools, e.g., Prometheus or self-service workflows.
Script 2: Creating a Spark Docker Image
The next script automates the creation of a Docker image for Spark. The image contains the necessary Scala, Spark, and data science packages, including two necessary Hadoop libraries for the AWS SDK and S3A.
- Docker makes it easy to control software dependencies, create reproducible execution environments, and run Spark clusters for different uses (prod vs. dev) on the same physical hardware.
- Run different versions of Spark at the same time or easily switch between versions to test upgrade paths.
- For expediency, the same Docker image is used for Spark workers and client nodes, whereas the client node (Jupyter) is the only one that needs all of the installed software.
Script 3: Creating a Spark Standalone Cluster Using Docker
The next script creates a Spark Standalone cluster running in Docker containers. Using Ansible, a Spark worker container is started on all nodes along with a Spark master and Jupyter notebook server.
This simple script demonstrates the creation of a Spark cluster programmatically, using Docker images to control the Spark environment and Docker plugins to ensure that FlashBlade storage is correctly attached for both the shared data hub and (optionally) local intermediate storage.
- The Pure Docker volume plugin creates and mounts volumes for node local storage on each worker.
- The Docker local volume plugin automatically mounts the existing NFS datahub filesystem for each container so that the host OS does not have to maintain the mount.
- This script uses Bash and Ansible to illustrate the mechanics involved in creating the cluster while keeping the logic simple.
Example: Machine Learning with K-means
KMeans is an unsupervised machine learning algorithm for clustering, which works by iteratively refining cluster centers. Each iteration of k-means calculates an update by reading back the full data set and there is a parallelized version available in Spark MLLib.
We use this workload as a simple way to demonstrate the ease of use and performance of Spark with FlashBlade.
Test data for this example is generated using scikit-learn’s make_blobs() function. The input data is created with 200 columns and then saved as a text file, as demonstrated in this Jupyter notebook.
The following Python notebook runs the KMeans clustering:
from numpy import array
from pyspark.mllib.clustering import KMeans, KMeansModel
# Load and parse the data
data = sc.textFile(“/datahub/kmeans_mllib/testdata”)
parsedData = data.map(lambda line: array([float(x) for x in line.split(‘ ‘)])).map(lambda r: r[:-1])
# Build the model (cluster the data)
clusters = KMeans.train(parsedData, 25, maxIterations=5, initializationMode=”random”)
KMeans operates by repeatedly calculating cluster centers and adjusting cluster assignments, with each iteration processing through the entire data set. The key to high-performance KMeans training is iterating quickly through the data set multiple times; this requires both fast storage and effective use of memory.
The screenshot below shows the FlashBlade UI after testing two different KMeans trainings in Scala code: uncached and cached data sets. The first test run shows the storage throughput without caching; each iteration re-reads the entire data set. The second run uses “inputs.persist()” so that only the first iteration reads in the data set and then subsequent iterations utilize the cached version of the data set if it fits within the distributed cluster RAM.
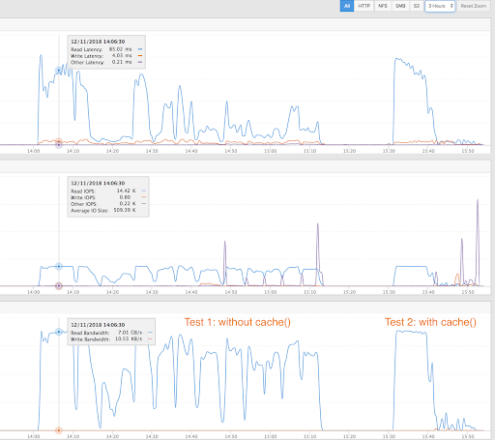
Fast storage is essential in the second test because half of the overall training time is spent in the first iteration, which must read the data into memory. The subsequent iterations are much faster because the data is read from memory, shifting the bottleneck from storage to the compute layer. Thus, Spark’s advantage of efficient memory caching does not reduce the importance of fast, persistent storage.
Example: Structured Data Analysis
This example demonstrates dataframe manipulation and analytics for the exploration of a data set. Specifically, this uses a Reddit data set containing 600M comments and determines the most frequent posters using PySpark dataframe manipulations.
The raw data is stored as 330GB of json, broken into 16 different S3 objects. The Spark notebook creates a dataframe from this data and then performs a series of basic structured analytics to calculate the top posters.
reddit_comments = spark.read.json(“s3a://spark-working/reddit”)
# Find the top authors by post count, excluding deleted authors.
reddit_comments.filter(“author != ‘[deleted]’”)
.groupBy(‘author’).count().orderBy(‘count’, ascending=False)
.take(20)
The screenshot shows the storage traffic the above query translates to: peak read throughput of 10GB/s and then sustained throughput of 6GB/s-7GB/s as the query is processed.
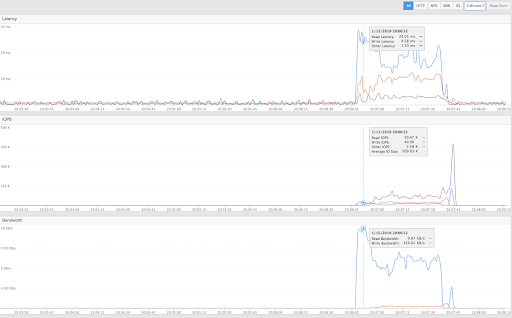
The query above completed in about one minute with 960 cores and a 15-blade FlashBlade system. One of the main advantages of Spark’s scale-out architecture is predictable scalability: If the query needs to complete in half the time, then, theoretically, the user can simply use twice as many nodes. FlashBlade supports highly concurrent workloads like Spark so that all compute and storage resources can scale out linearly.




