



High performance computing (HPC) workloads using electronic design automation (EDA) tools require a high magnitude of compute resources to run jobs in a 24/7 queue for design and manufacturing processes. Similarly, semiconductor organizations require the ability to quickly provision infrastructure on demand to accelerate the chip design process and drive faster time to market.
However, on-premises data centers are limited in their ability to scale compute cores on demand, which is required during chip simulation. As a result, many organizations are leveraging the public cloud to provision compute resources on demand for modeling and simulation purposes. Public cloud providers like Microsoft Azure provide the elasticity to scale compute cores, network, and data storage in different regions across the globe.
Intellectual property (IP) for chip design and manufacturing is the crown jewel for semiconductor companies. As a result, semiconductor companies that design and manufacture systems on chip (SoCs) are hesitant to move data generated from chip design projects to the public cloud for security reasons. There could be legal ramifications if the semiconductor company doesn’t have control of the data locality.
Accelerating Semiconductor Design Pipelines with Pure Storage FlashBlade//S
Mitigate Security Risks with a Connected-Cloud Architecture
With a connected cloud architecture, businesses can mitigate security risks for IP and chip design data. A connected cloud also provides the elasticity to extend into Azure Cloud for cloud bursting on demand or always-on, sustained workloads. Read more about the performance and functionality of EDA tools running in Azure VM with data hosted on FlashBlade® in an Equinix location in the blog post, Scaling Software Builds in Azure with FlashBlade in a Cloud-Adjacent Architecture .
Seamless Data Mobility
In this blog post, we’ll focus on moving and staging data seamlessly from an on-premises data center to an Equinix data center for cloud consumption during the chip design and development process. FlashBlade supports bi-directional file system replication between on-premises and the Equinix data center. File system replication allows organizations to move relevant SoC data for internal development. It also enables hosted customers to scale compute resources in Azure on demand.
The array-level file system replication between the on-premises data center and FlashBlade deployed at Equinix is tunneled through the virtual router at Equinix as shown in the diagram below. Data doesn’t leave the on-premises data center over the external network/internet to reach the FlashBlade in the Equinix data center. The company and the end users have complete control over the FlashBlade and data locality in the Equinix data center. A separate subnet needs to be configured on the on-premises FlashBlade to communicate with the FlashBlade in the Equinix data center.
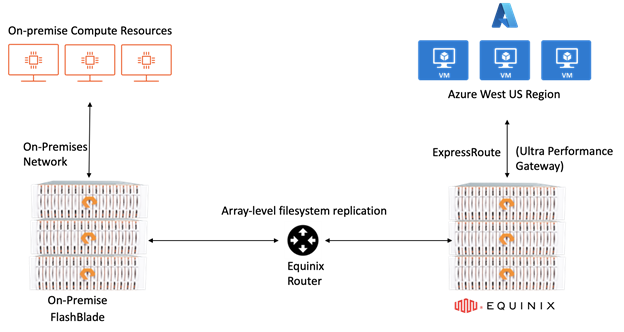
A performance test of file system replication between the on-premises FlashBlade device and the FlashBlade in the Equinix data center demonstrated an 8GB/sec transfer speed for 2.3TB that completed in less than one minute. Both the source and destination locations also exhibited a data reduction of 2:1 for most of the chip design data set on the respective FlashBlade devices.
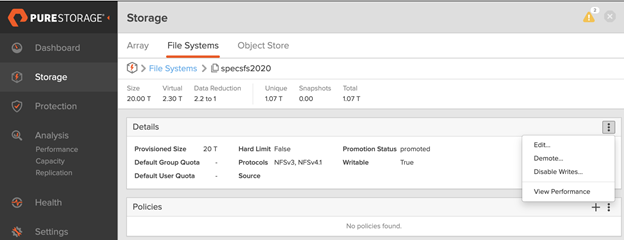
The FlashBlade in the Equinix data center is the replication target. The replicated file system in the target FlashBlade is read-only to the Linux hosts mounted over NFS. It’s in a promoted state as shown in the figure below.
As replication is based on a common snapshot, the target file system can be demoted on the FlashBlade deployed at Equinix as a source that can perform read and write operations from Azure VMs. The original source file system in the on-premises FlashBlade gets promoted to a read-only file system as shown in Figure 3 below.
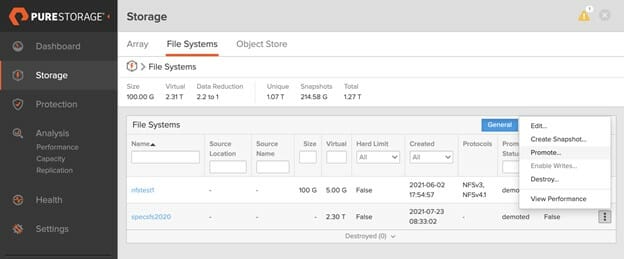
Array-level file system replication also has the ability to failover to the target FlashBlade in the Equinix data center where it’s promoted as the source. The on-premises FlashBlade will be demoted as the target. This feature allows FlashBlade to replicate the changes made in the file system in the Equinix data center back to the on-premises data center for security reasons.
The entire file system replication process can be automated with zero storage touch between the on-premises FlashBlade and the Equinix-hosted FlashBlade using Ansible playbooks. The failover and failback capabilities can also be achieved using Ansible playbooks.
Data has gravity. Array-level file system replication allows you to stage data for cloud bursting in Azure Cloud and the Equinix data center. Fast data replication between FlashBlade devices and data reduction at the source and destination offer rapid data mobility in a cost-efficient manner.
Watch this video for a full demo of data mobility for HPC and EDA workloads from on-premises to Azure Cloud.
Enabling EDA workloads in the cloud isn’t very straightforward. See how Pure can help you accelerate EDA workloads while addressing concerns around IP security, data governance, costs, and cloud lock-in.
What Do AI Teams Need to Succeed?

Written By:
Next-level EDA Workloads
Get the performance, security, and seamless mobility your data demands.



