



This blog on generative AI initially appeared on Medium. It has been republished with the author’s credit and consent.
In this post, I will talk about generative AI and RAG from data infrastructure’s point of view. Let’s start with the basics.
Generative AI predicts and generates the next token/pixel/code within context. Large language models (LLMs) such as ChatGPT and Llama are some of the most popular generative AI for text generation. Multimodal (MMLM) generative AI which supports text, image, and video as an input and output is getting better and better.
Many generative AI models perform surprisingly well (close to or even exceeding human level in some cases); however, sometimes they also generate content that is not true (hallucinations) or up to date. This is where retrieval-augmented generation (RAG) can be very useful. By retrieving relevant information from a database of documents and using it as a context, RAG enhances the generation to produce more informed and accurate outputs.
Why Generative AI Depends on Data Infrastructure
Generative AI models are huge. LLMs with tens to hundreds of billions of parameters are common. Each parameter in a model is a floating point number. A full-precision float number takes 32 bits (4 bytes) in computer memory.
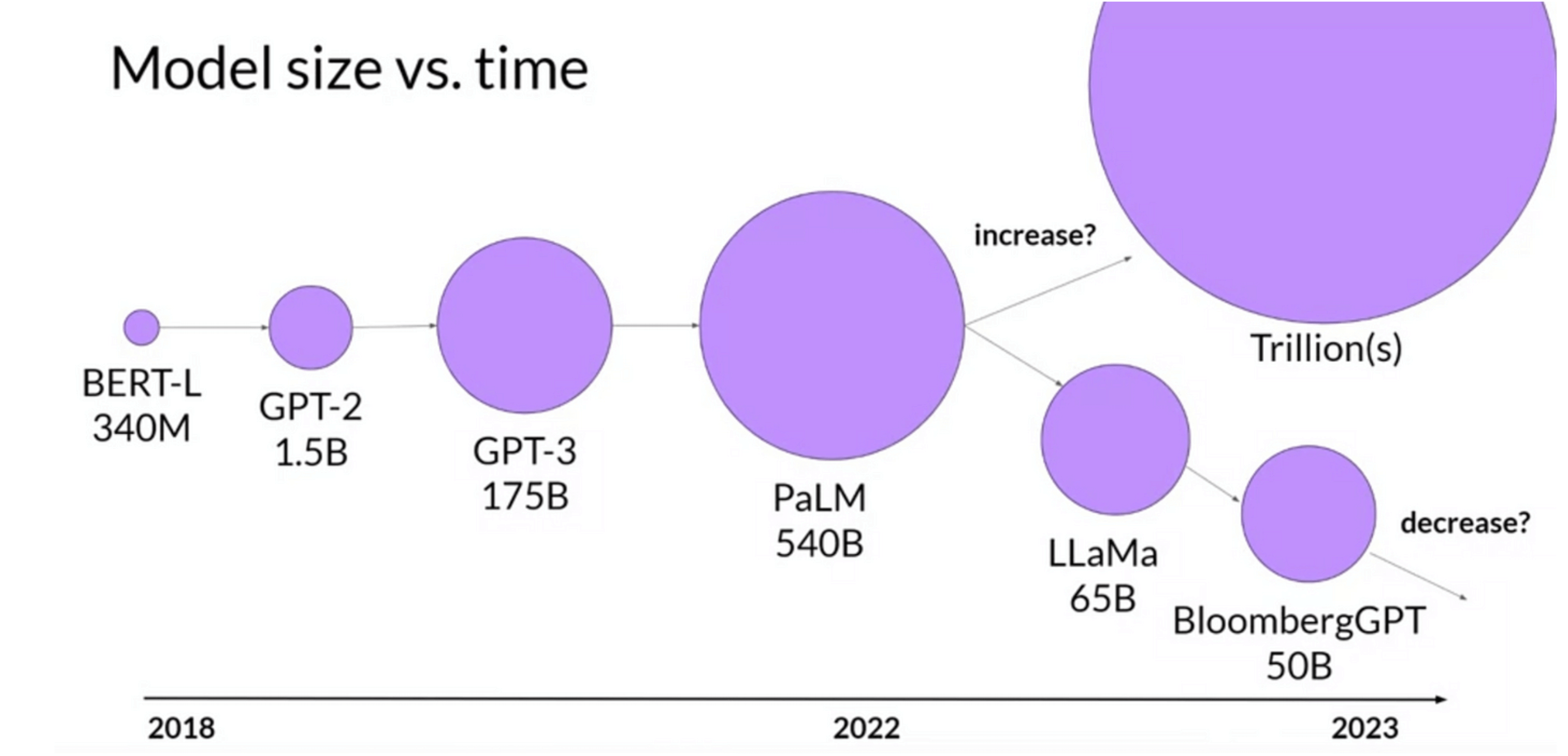
Source: https://www.coursera.org/learn/generative-ai-with-llms
Therefore, 4GB memory is needed to load a model with 1 billion parameters. And this is only to load the model; extra memory is required to train it. It’s estimated that for every 1 billion parameters, 24GB of GPU memory is needed for training. A bare minimum of 1680GB GPU memory is needed to train the 70B Llama 2 model. This means a minimum of three NVIDIA DGX H100 GPU servers (eight GPUs, 640GB GPU memory per server) is required. However, training would take years with this. In practice, many more GPUs are used to train a large model in reasonable time. The GPT-3 model was trained on 10,000 GPUs. Most AI customers I’ve worked with have tens to hundreds of GPU servers.
How to Build Data Infrastructure for Training Generative AI
GPUs are powerful and expensive. From data infrastructure’s point of view, the question is how to keep the GPUs busy with fast data. First, I think we need to understand the data I/O patterns in a GPU-powered AI system. Both I/O reads in training and writes in checkpointing are highly parallel and throughput bound. I/O requirement also depends on model architecture, hyperparameters such as batch size, and GPU speed. For a DGX H100-based large system, we can refer to the guideline for storage performance from the NVIDIA SuperPOD reference architecture:
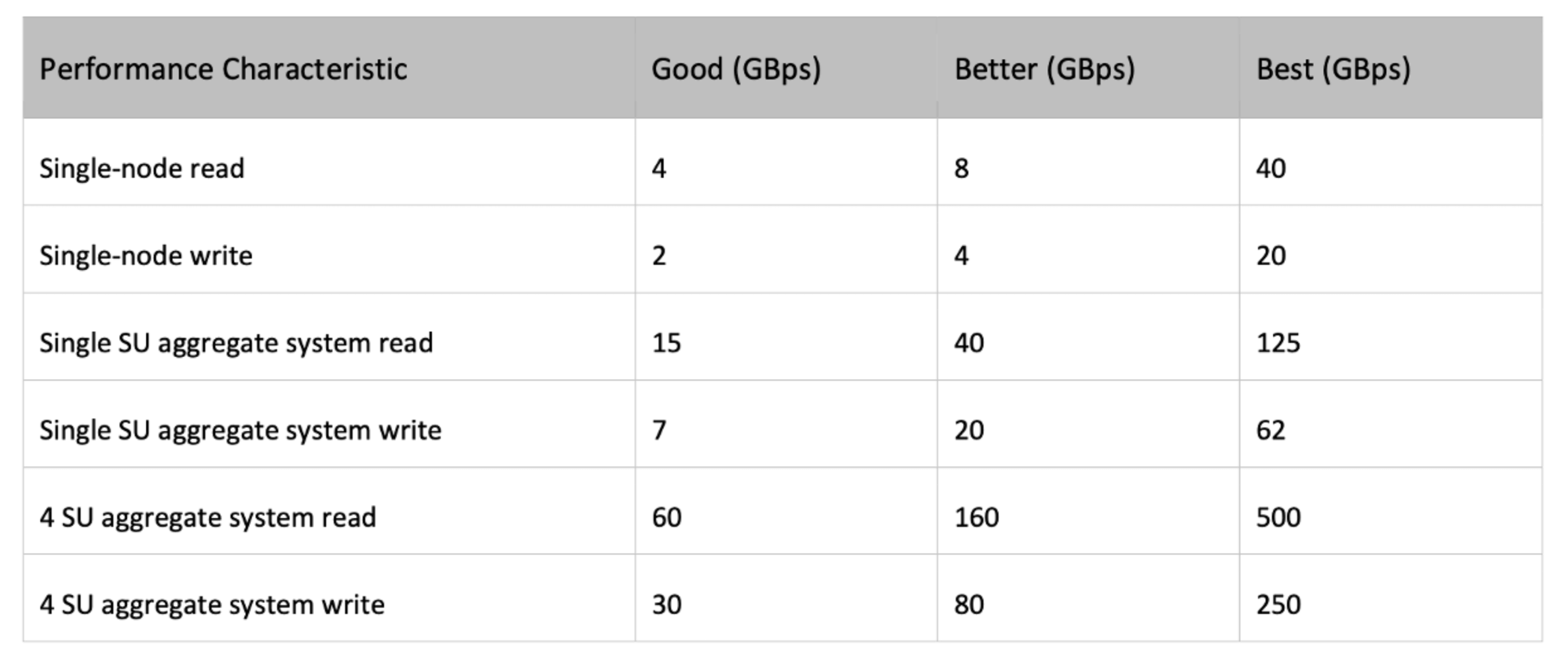
Source: https://docs.nvidia.com/https:/docs.nvidia.com/dgx-superpod-reference-architecture-dgx-h100.pdf
Some customers I’ve worked with simply use the “Better” column as a reference, whereas some prefer proof of concept (POC) tests.
It’s beyond the scope of this blog, but I’d like to highlight that besides I/O performance, enterprise storage features such as non-disruptive upgrades, data protection, and multiple protocol support, especially NFS and S3, are also important when choosing data storage for a generative AI system.
So far we’ve been focusing on training. How about inference, or RAG, in particular? How do we build optimal data infrastructure for a RAG-powered generative AI application?
RAG and Data Infrastructure
RAG combines external information sources with LLMs. It’s an inference phase integration in the generative AI project lifecycle. This means we don’t have to go through the expensive training phase, which could run for hours to weeks, to include validated and latest information to LLM generation. Instead of sending user input query directly to an LLM, RAG first retrieves validated information from external data sources such as databases and documents and then sends this information together with the user query as context to the LLM. This leads to better generation.
For example, I asked “What is Pure Storage Evergreen One?” to a 7B Llama 2 model. I got the following response, which is far from correct:

Llama 2 response without RAG.
Llama 2 does not have proper knowledge about the question because it was not included in the data sets used to train the model. This is common for many enterprises whose domain knowledge is not included in the LLMs trained with public data sets.
To improve the response, I used RAG with the Evergreen//One™ HTML page as the external data source.

Built to Scale
with Evergreen
See how Evergreen and Pure Storage simplify
storage management across any environment.
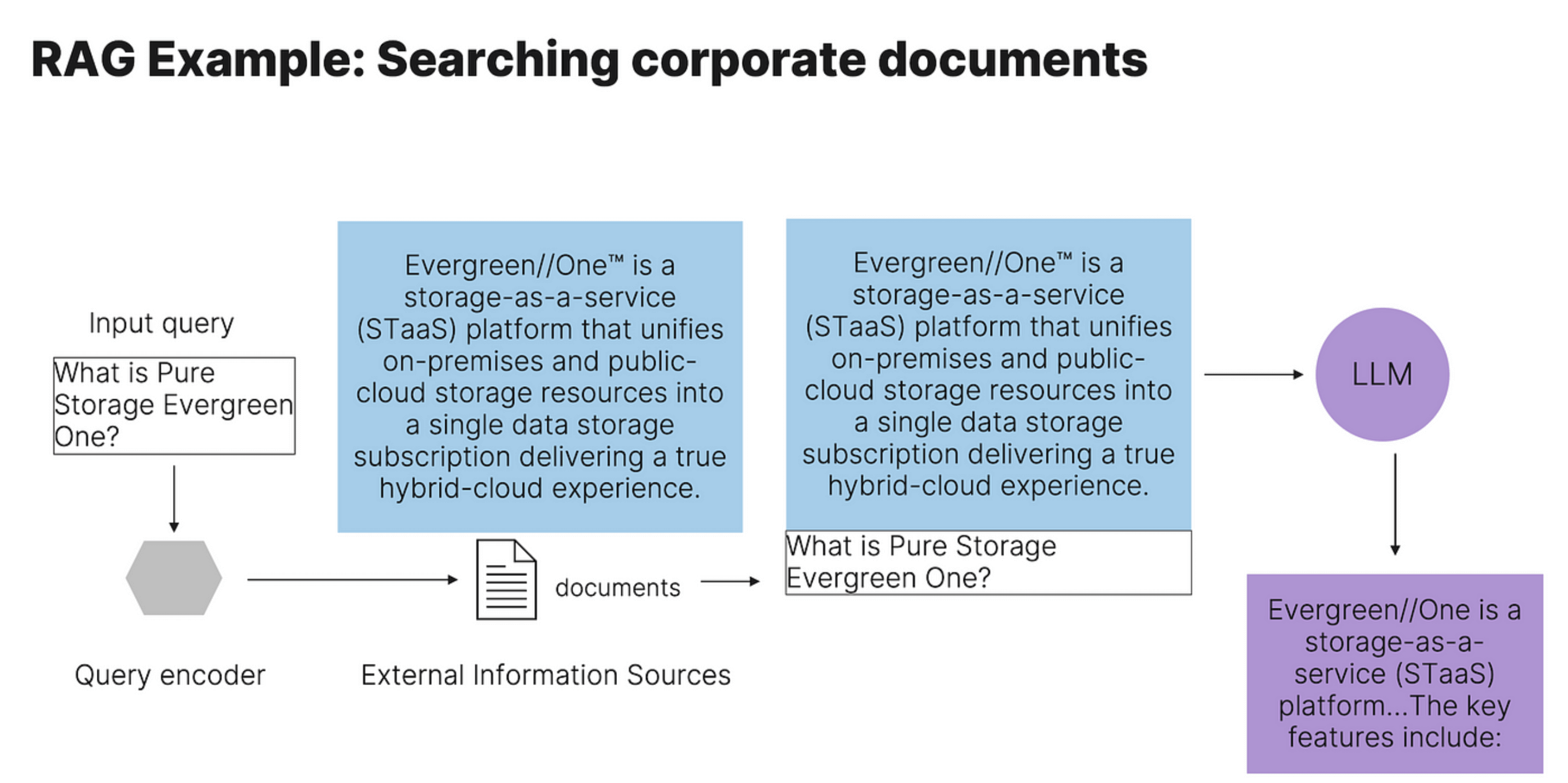
RAG example: searching corporate documents.
With RAG, I got a much better response.
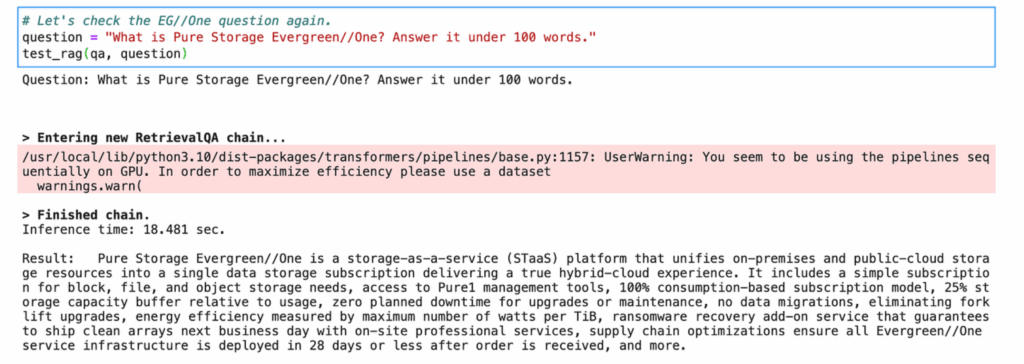
Llama 2 response with RAG.
Data Infrastructure for RAG
RAG encodes external data (the HTML page in the example above) so that it can easily retrieve the relevant parts of the data on query. The best option for storing and retrieving external data for RAG is a vector database, as a vector database supports similarity search that enables RAG to quickly retrieve data that is relevant to user query. There are multiple vector database options, both open source and commercial products. A few examples are Chroma DB, Pinecone, Weaviate, Elasticsearch with the vector scoring plugin, and Pgvector—PostgreSQL with vector extension.
I/O pattern for these vector databases is different from generative AI training. We need high-throughput writes for ingestion and low-latency reads for retrieval. While NFS is the protocol of choice for training, we may use block, NFS, or S3 here depending on the vector database software. We may also need something like Portworx® or a CSI driver to provide persistent storage when running the vector database on Kubernetes, which is quite common.
Like any database, we should also plan carefully on the data “schema” in these databases. What are the considerations when storing different types of data, including HTML, PDF, PowerPoint, and Word, in a vector database? Should we include metadata such as modification time and document structure? How about tables in the documents? These are all important practical designs for building data infrastructure for RAG.
Since data is encoded as high-dimensional vectors, data can expand to multiple times bigger stored in a vector database for optimal RAG performance. This is also important for storage sizing.
Conclusion
In this blog, I briefly introduced generative AI, RAG, and the unique impacts and requirements they impose on data infrastructures. It’s rare for an individual (including myself) or even a team to master data infrastructure, generative AI and RAG applications, and everything in between. I try to connect the dots within my knowledge, and hopefully, this helps.
In my other post, I shared more examples and dug into technical details of those generative AI applications, RAG, and their data infrastructure.

ANALYST REPORT,
Top Storage Recommendations
to Support Generative AI

Written By:
Power Your AI Efforts
Learn how the Pure Data Storage Platform can help you accelerate AI adoption.



