

Summary
This article provides a step-by-step guide for using the Pure Fusion API with Visual Studio Code, GitHub Copilot, and the py-pure-client package for efficient managing and reporting of storage space.


Recently, I was faced with a common issue during a major project: responding to a customer’s request for proposal (RFP). They needed something that we couldn’t easily deliver off the shelf: to provide showback/chargeback reports to departments and application owners based on how much data they were storing on some storage arrays.
The request was pretty straightforward, but the solution was not.
Pure Storage does provide some great reporting capabilities in Pure1®, but not precisely what the customer wanted to do: Tag volumes with a corporate cost center code and then roll up a spreadsheet for finance at the end of the month that would be easy to process. I prefer to provide a complete solution without a lot of customisation, so I thought it was time to actually develop some code instead of letting a customer do it. What a great opportunity to leverage the new Pure Fusion™ API.
What My Customer Wanted
In an operational environment, it’s easy to enforce uniformity using automation, scripting, and standards. But in the wild west of an existing environment migrating into a new platform, you can’t rely on a good naming convention for hosts, volumes, or basically anything. And any unpredictable changes are a really bad idea.
So this project needed to do two things: allow objects to be tagged flexibly so that we could cope with legacy systems, and then report space consumption dynamically to cope with moves/adds/changes.
What I Wanted to Deliver
Simplicity, if possible. Allow the scripts to be run automatically with no user intervention. Work in security requirements—that means using a proper authentication scheme and putting the credentials into the environment from a password vault if possible. Easy use by finance: output a spreadsheet every month that can easily be ingested into a finance package.
How Did I Approach the Development?
I wanted a springboard environment. I work on complicated deals at Pure Storage, so there’s not a lot of free time to think or plan and learn on the job. Luckily, I have a captive lab environment that lets me put all of the right elements in place like a real enterprise environment—dedicated management LAN, Active Directory and certificates for TLS/SSL encryption of traffic, VMware vSphere—a real prototyping environment.
It’s been a while since I did any code development, and doing dev work while doing my day job seemed overwhelming. Leveraging AI turned out to be a great decision, as my toolchain of choice included items I hadn’t used for a while (or ever!).
I took a leaf out of my colleague Simon Dodsley’s book with the py-pure-client package for tool development. Python packages make it child’s play to create Excel spreadsheets and populate them with my data in an easy way, so the end result is more natural for people in a finance department to consume and manage.
And our Python client is updated quickly when it comes to staying in sync with new revisions of Pure Storage APIs. And with Pure1, FlashArray™, and FlashBlade® innovating rapidly as Pure Fusion develops, that was the way to move this project along.
GitHub Copilot
I decided on Visual Studio Code with the GitHub Copilot plugin to help me write and refactor code in Python. This made it super easy to prototype, and debugging was much easier with a programming twin looking out for my mistakes!
To Do List
Here’s a comprehensive guide to what I did—it should help you get started:
- Development Environment:
- I installed Microsoft Visual Studio Code (I used a Mac with MacOS Sequoia and Windows 11) with Python, GitHub, and copilot.ai extensions.
- Cloned my code repo (STAAS stands for “storage as a service”).
- Setting Up Dependencies:
- Put your arrays into a fleet using Pure Fusion—critical for being able to run the scripts. They just talk to one array and let Fusion marshal the information from all of the other arrays in the network, which you can see in Figure 1.
- Ensure you’re using Purity//FA REST API version 2.41 or above. That’s the minimum for Pure Fusion fleets, presets, and workloads, and it comes with Purity//FA 6.8.5.
- Install the py-pure-client Python SDK version 1.62.0 or above to support the required Fusion API calls. My Python code needs a few other modules, but the information on what’s current is in my repo.
- Environment Configuration:
- Get an API key set up on the FlashArray that you will use for reporting. This must be a user in the Management Directory Service. I created an API key under my login name, and in this environment, my user account is in the storage_admin group.
- Set environment variables PURE_USER_NAME and PURE_API_TOKEN with administrative access levels. When running the script, you’ll need to set these environment variables up—of course, UNIX and Windows do this differently!
- Configuration data is stored in STAAS_Tagging.xlsx under the worksheet named “Fleet.” The script takes a configuration spreadsheet filename on the command line—you can put this somewhere safe that the script only has read access to. I put it in a config folder, but you can place it anywhere to suit your environment.
- Running the Scripts:
- The scripts require some arguments: –config (for both scripts) and –report (a folder to put the report spreadsheets in for staas-reporting.py).
- staas-tag_vols.py performs the tagging, connecting to an array in the Pure Fusion fleet based on rules defined in the configuration worksheet.
- staas-reporting.py generates a spreadsheet with worksheets for detected tags and untagged volumes.
- You might want to run this in a container in production, with a read-only config spreadsheet and a writable folder for the output spreadsheet, that are both accessible by the financial end-users (rather than storage admins).
- Using the Pure Fusion API:
- Ensure the FUSION_SERVER DNS entry points to a server that is part of the fleet and that all relevant FlashArrays are joined into the fleet..
- Report Generation:
- Generated reports are date/time stamped for ease of external space rating over time.
- Use Visual Studio Code’s integrated terminal to run and debug scripts.
- Best Practices:
- Store configuration and tagging rules in dedicated spreadsheets for manageability.
- Regularly update environment variables and dependencies to maintain security and functionality.
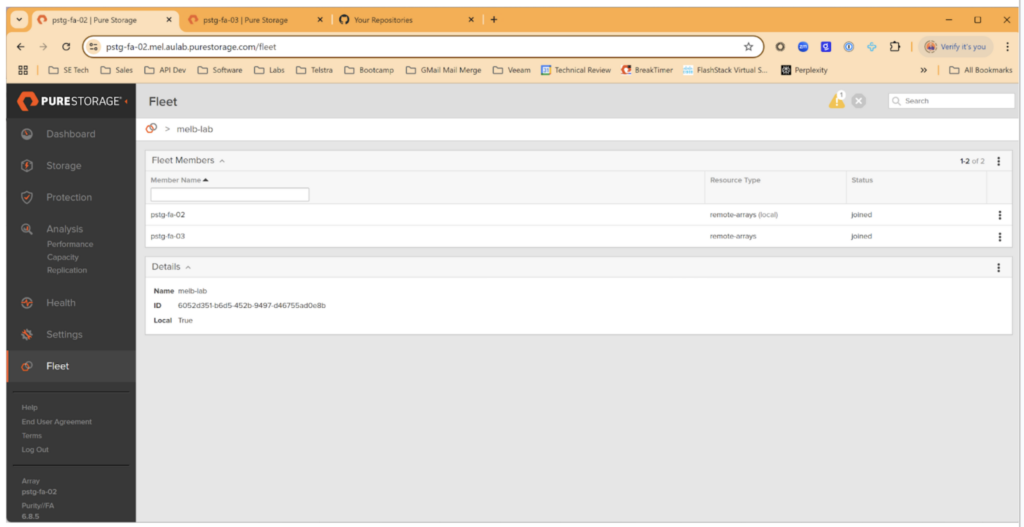
Figure 1: Fusion with all of the information from all of the other arrays in the network
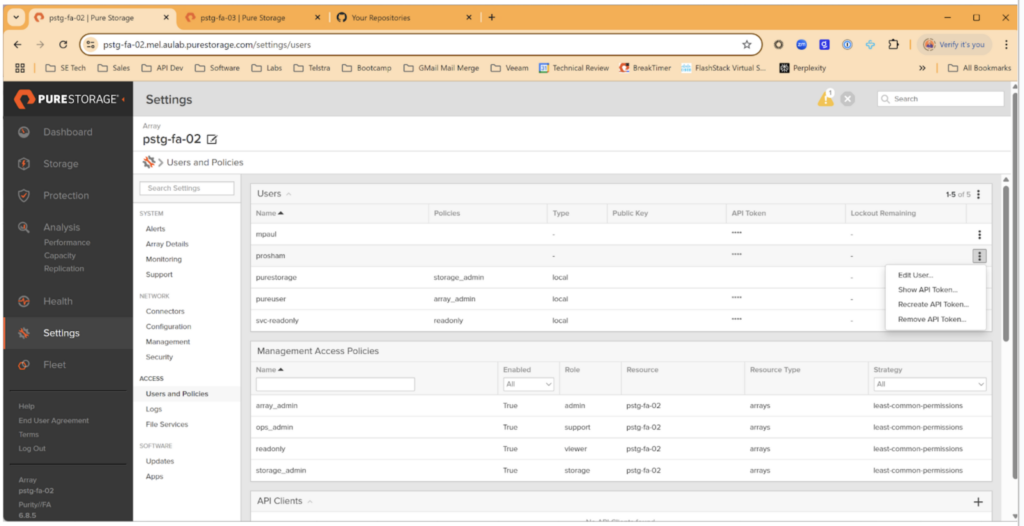
Figure 2: I created an API key under my login name, and in this environment, my user account is in the storage_admin group.
By following this guide, any storage engineer should be able to, quickly and effectively, develop reporting or management tools for Pure Storage FlashArrays, leveraging modern development practices and automation tools.
What Did I Learn?
Modern software development pipelines are pretty accessible! I hadn’t really done any dev work for external consumption for a while, so the tools took some getting used to.
Surprise! When you prepare all software with a platform like Github, and bring that mindset of sharing (and maybe even open source), you’ll build utilities that are more accessible. I found that the AI tools were a big help here to get things going quickly without needing to backtrack.
Visual Studio with all of its’ plugins was a wonderful addition (and my editor works with vi keystrokes like UNIX in the 80s, I’m such a dinosaur). The debugger and ability to explore the APIs in real time really helped me out.
The Pure FlashArray API enhancements with Fusion make things super easy to design for multiple arrays, and soon, multiple fleets and platforms like FlashBlade, all from a single entry point. I love the way that the control plane for storage is around everywhere that Purity software is, including in the cloud with Cloud Block Store.
I’m now much more confident with Python, even if I’m 10 years late to the party. Thanks, Garth Kidd (a colleague from many jobs ago) for planting the seed.
Last but not least, Github Copilot tied it all together to get me into productive mode, so I could push the tool further even while stealing time from my day job.

Applications and Databases
Simplify management, boost performance, and dramatically cut costs
Automate Everything
Supercharge your fleet-wide storage automation.



