



This article on creating scalable and reliable Kubernetes logging originally appeared on Medium. This blog has been replublished with the author’s credit and consent.
Building a basic logging solution for Kubernetes could be as easy as running a couple of commands. However, to support large-scale Kubernetes clusters, the logging solution itself needs to be scalable and reliable.
In my previous blog post, I described an overview of my Kubernetes monitoring and logging solution. At that time, I used a basic setup for logging: logs collected by Fluentd on the Kubernetes node are directly sent to an Elasticsearch and Kibana cluster for search and visualization, with both Fluentd and Elasticsearch running on the Kubernetes cluster itself. This is an easy setup that works for small clusters. Once we move to large production clusters, it will have challenges such as:
- Fluentd may drop logs (data loss!) if Elasticsearch is down or cannot catch up indexing the incoming logs.
- Log input and output are tightly coupled, therefore difficult to manage.
- Logs are only stored in Elasticsearch, therefore difficult to extend to other tools, such as Apache Spark for general log processing and analytics.
In this blog post, I will describe how I addressed these challenges by building a scalable and reliable Kubernetes logging solution with scalable tools such as Fluentd, Kafka, Elasticsearch, Spark, and Trino. I will also highlight the role a fast object storage like FlashBlade® S3 plays in this solution. The final architecture looks like this:
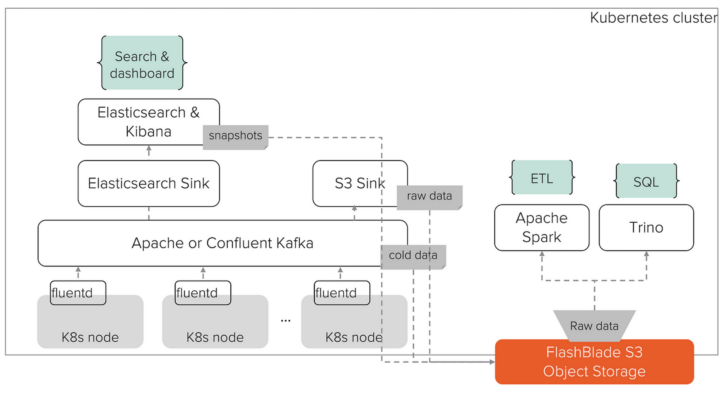
Scalable Kubernetes logging.
Apache Kafka as Pipeline Buffer and Broker
The first thing we need to do is de-couple log inputs (Fluentd) and outputs (Elasticsearch). This adds flexibility and scalability to the logging pipeline. Apache Kafka is the most popular solution for this. This setup requires a running Kafka cluster. Please refer to my blog post on how to set up an open source Kafka cluster on Kubernetes. Another option is to use Confluent Kafka for Kubernetes. One nice feature of Confluent Kafka is its support for tiered storage, which allows Kafka to offload cold data to remote object storage like FlashBlade S3. More on this later. For now, let’s focus on Fluentd and Kafka integration.
The easiest way to get started is to use the Kafka2 plugin from the Fluentd Kubernetes Daemonset repo, which includes pre-built Docker images and Kubernetes spec examples. The Fluentd-Kafka2 Docker image supports basic configuration using environment variables. For example, Kafka brokers and topics can be set in Kubernetes spec file like this:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
<span style=“font-weight: 400;”>containers:</span> <span style=“font-weight: 400;”>– name: fluentd</span> <span style=“font-weight: 400;”> image: fluent/fluentd–kubernetes–daemonset:v1.12–debian–kafka2–1</span> <span style=“font-weight: 400;”> env:</span> <span style=“font-weight: 400;”> – name: FLUENT_KAFKA2_BROKERS</span> <span style=“font-weight: 400;”> value: “kafka-headless.kafka:29092”</span> <span style=“font-weight: 400;”> – name: FLUENT_KAFKA2_DEFAULT_TOPIC</span> <span style=“font-weight: 400;”> value: “k8s-logs”</span> |
Since I need more controls on Kafka producer acknowledgement, timestamp format, and log source separation, I extended the config file using Kubernetes ConfigMap. After these, logs are delivered into multiple Kafka topics based on their source. Additional metadata, such as ingestion timestamp and source tag, are also attached by Fluentd. These will be helpful later when we process the logs with Elasticsearch and Apache Spark.

BUYER’S GUIDE, 14 PAGES
Reevaluating Your Virtualization Strategy?
Explore your options in our guide to modern virtualization.
Shipping Logs from Kafka to Multiple Outputs
To ship the logs from Kafka to its final outputs, in this case Elasticsearch and S3 object storage, I use Kafka Connect Elasticsearch sink and S3 sink. Kafka Connect is a tool for scalably and reliably streaming data between Apache Kafka and other data systems. Each connector runs as its own Kafka consumer groups in distributed mode, meaning scalability and reliability are built in. Because log input and output are decoupled by Kafka, it is easier to extend the system. For example, there are over 100 connectors in the ecosystem that ships data from Kafka to different outputs.
By running the connector pods as Kubernetes Deployment, we can easily scale the logging pipeline to match the growth of the Kubernetes cluster. Below is an example of Fluentd and Kafka Connect running in a Kubernetes cluster.
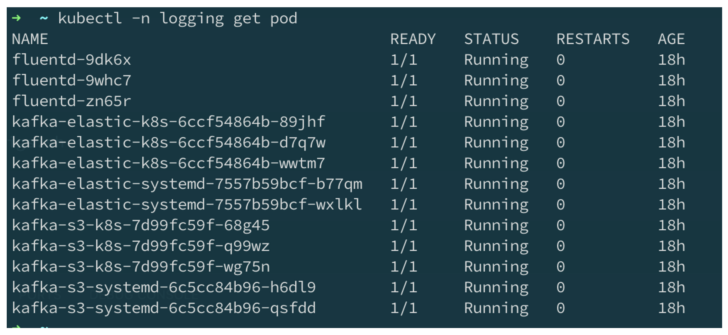
Fluentd and Kafka Connect running in Kubernetes.
Confluent Kafka Tiered Storage with S3
If using Confluent Kafka, its tiered storage feature, especially together with FlashBlade S3, makes Kafka even more scalable, reliable, and easy to operate in a Kubernetes environment. The basic idea is to offload cold data from Kafka brokers to remote object storages, so that Kafka only needs to manage minimum local data (hot data) in the brokers. This makes Kafka broker pods very lightweight, therefore easier to scale and operate. Particularly, data re-balancing could be several fold faster. This also reduces storage cost because Kafka has no need to maintain multiple replicas for data in S3.
Here is an example of setting up FlashBlade S3 for Confluent Kafka tiered storage using the Confluent for Kubernetes operator:
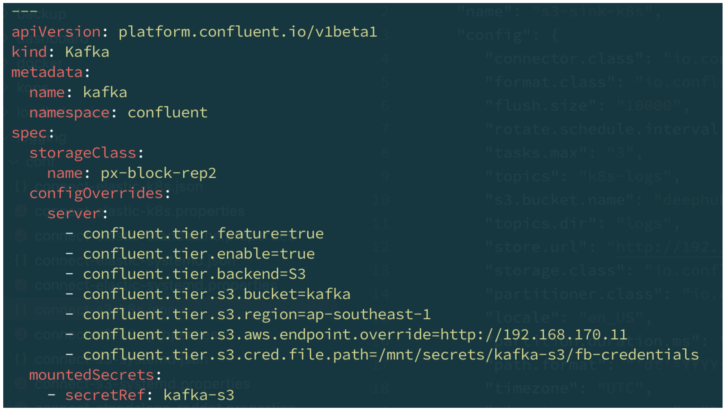
Confluent Kafka tiered storage with FlashBlade S3 configuration.
Once deployed, we can confirm FlashBlade S3 has been configured as tiered storage backend on Confluent UI.
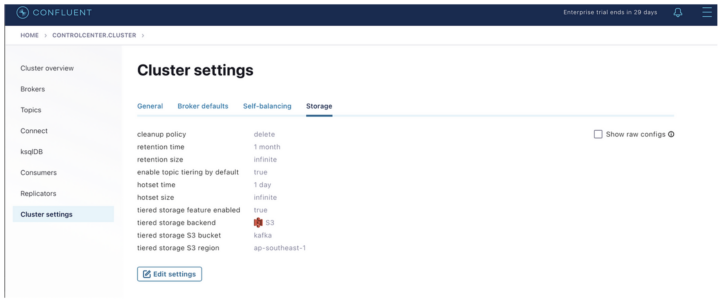
Confluent Kafka tiered storage with FlashBlade S3.
Kafka clients still access all the data through Kafka. If a request hits cold data, Kafka will download it from the remote object storage, cache it, and serve it to the client. FlashBlade S3 is a supported tiered storage target. Unlike Amazon S3 and other object storages, FlashBlade S3 is designed to be very fast, so even if the data is stored remotely, serving cold data could be close to as fast as hot data.
Log Analytics with Elasticsearch, Spark, and Trino
Large Kubernetes clusters could generate millions of log entries every hour or sooner. Analyzing those logs itself is a big data problem. Elasticsearch, Apache Spark, and Trino are some of the most popular scalable tools for log analytics.
I use Elasticsearch for streaming log analytics, searching, and dashboarding. Using the Elastic Cloud on Kubernetes, deploying Elasticsearch in Kubernetes can be as easy as a couple of commands.
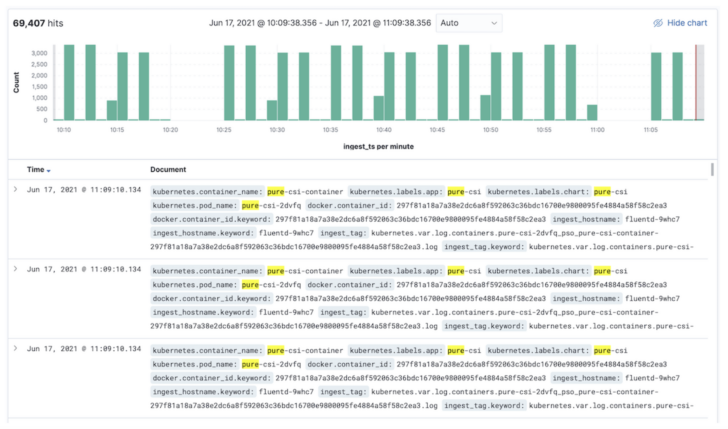
Searching Kubernetes logs in Elasticsearch.
Elasticsearch Searchable Snapshots with S3
Like Confluent Kafka, Elasticsearch also supports offloading cold and frozen data to remote object storage. Originally, snapshots in S3 were only supported for backup purposes, with the latest 7.13 release, the snapshots have become searchable!
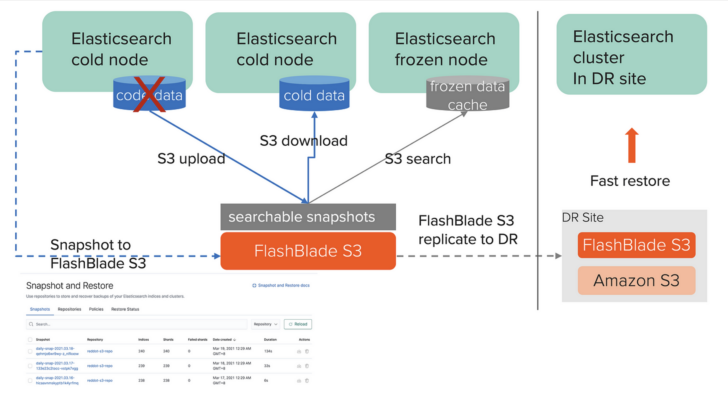
Elasticsearch searchable snapshots with FlashBlade S3.
By keeping minimum data locally, searchable snapshots make it easier to operate and scale Elasticsearch and reduce storage cost while increasing search speed for cold and frozen data with FlashBlade S3.
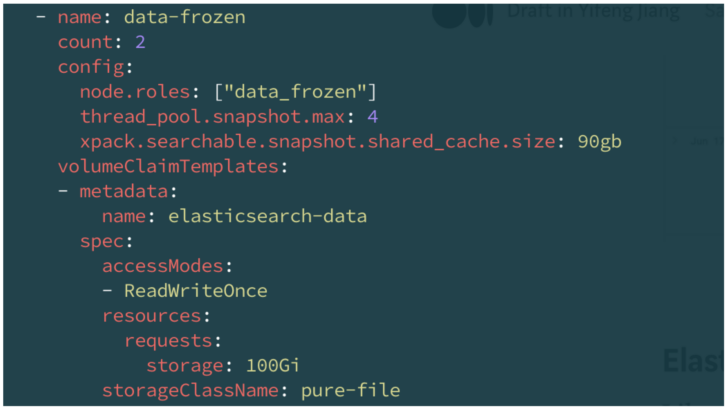
The most important config for searchable snapshots is to set the shared cache storage and size in Elasticsearch frozen node. In the example below, I have set 90GB out of the 100GB FlashArray™ backed persistent volume for the cache.
We can then create a searchable snapshot and store it in the FlashBlade S3 repository.
|
1 2 3 4 5 6 7 8 9 |
<span style=“font-weight: 400;”>POST /_snapshot/reddot–s3–repo/demo/_mount?storage=shared_cache</span> <span style=“font-weight: 400;”>{</span> <span style=“font-weight: 400;”> “index”: “logstash-2021.05.20”,</span> <span style=“font-weight: 400;”> “renamed_index”: “logstash-2021.05.20-mounted”</span> <span style=“font-weight: 400;”>}</span> |
Searching a searchable snapshot index is the same as searching any other index. If data is not available locally, Elasticsearch will download the index from S3, cache it locally, and serve from there for future requests.
As you can see below, I have created three indices: the original, one fully restored from a regular snapshot, and one from searchable snapshot. The index from searchable snapshot uses zero byte on disk, indicating the data was served from the S3 repository.
|
1 |
<span style=“font-weight: 400;”>GET /_cat/shards/logstash–2021.05.20*/?v&h=index,shard,prirep,state,docs,store,node</span> |
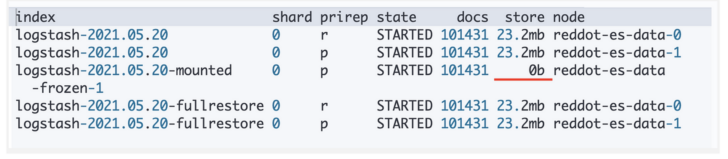
Index from searchable snapshot using zero byte on disk.
ETL and SQL Analytics
While Elasticsearch is very good at streaming log analytics, it is not for all the log analytics needs. For example, we use Apache Spark and Trino for ETL and SQL analytics. For that, we will need to store the raw logs in S3 first. As described above, we use Kafka Connect S3 sink to ship the logs to S3 in its raw json format. We also separate/partition the data by source and ingestion time for easy processing. The logs are stored in S3 like this:
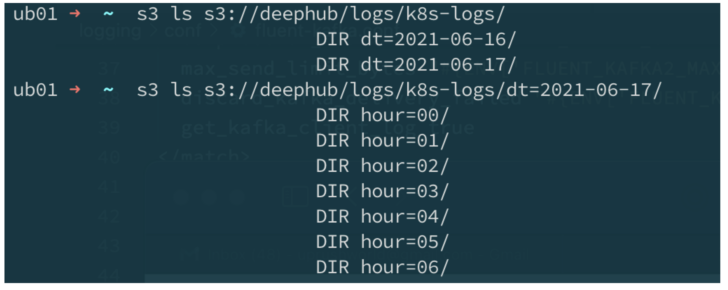
Kubernetes logs stored in FlashBlade S3.
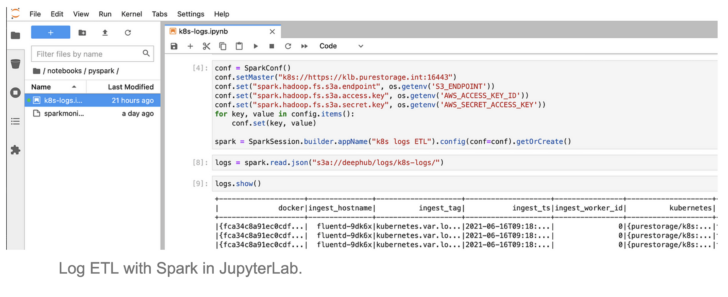
Once logs are stored in the S3 bucket, I can explore the data in JupyterLab notebook using Spark.
Log ETL with Spark in JupyterLab.
I can also use Trino to run SQL queries against the json data directly.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
<span style=“font-weight: 400;”>CREATE TABLE IF NOT EXISTS k8s_logs(</span> <span style=“font-weight: 400;”> ingest_ts varchar,</span> <span style=“font-weight: 400;”> log varchar,</span> <span style=“font-weight: 400;”> kubernetes ROW(</span> <span style=“font-weight: 400;”> container_image_id varchar,</span> <span style=“font-weight: 400;”> container_name varchar,</span> <span style=“font-weight: 400;”> ...</span> <span style=“font-weight: 400;”> ),</span> <span style=“font-weight: 400;”> dt varchar,</span> <span style=“font-weight: 400;”> hour varchar</span> <span style=“font-weight: 400;”>)</span> <span style=“font-weight: 400;”>WITH (</span> <span style=“font-weight: 400;”> format=‘json’,</span> <span style=“font-weight: 400;”> partitioned_by = ARRAY[‘dt’, ‘hour’],</span> <span style=“font-weight: 400;”> external_location=‘s3a://deephub/logs/k8s-logs’</span> <span style=“font-weight: 400;”>);</span> |

SQL analytics with Trino.
Because all the tools, including JupyterLab, Spark, and Trino, are running in the Kubernetes cluster, I can start these analytics immediately and scale it easily. My previous blog posts here and here describe how to run Spark and Trino (formerly PrestoSQL) with Kubernetes and S3.
Summary
In this blog post, I described how I scaled my logging solution to collect, store, and process a large amount of logs generated in the Kubernetes cluster. While it was built for Kubernetes logging, the solution is flexible and suitable for other big data use cases as well.
To make the solution scalable and reliable, the core tools we use need to be scalable and reliable. The cloud-native trend (public cloud or on-premises Kubernetes) has encouraged traditional big data systems like Kafka and Elasticsearch to move away from local data replication toward remote object storage. Because of this, a fast object storage like FlashBlade S3 plays an important role in the solution.
Scaling the logging solution has been much easier.




