


This article originally appeared on Medium.com and is republished with permission from the author.
Dremio is a rapidly growing scale-out analytics engine that is part of a new generation of data lake services, emphasizing the power and flexibility of disaggregated storage like FlashBlade®. Two performance-oriented technologies power Dremio queries: Apache Arrow, a quick in-memory data format, and Gandiva, a high-performance toolset for querying Arrow data.
What is the advantage of using Dremio?
A key advantage of using Dremio is the ability to query data in place on FlashBlade, using either NFS or S3, instead of needing to import or copy it. This contrasts with legacy data warehouses which rigidly couple compute and storage, limiting ability to scale resources or clusters as needed and creating data silos.
A summary of the advantages of Dremio and FlashBlade together:
- Cloud-native disaggregation of query engines and storage, making it simple to independently scale, operate, and upgrade systems.
- Ability to query filesystem and object data together, allowing you to store data at the best location without requiring extra copies.
- Support for Hive tables enables in-place migration from legacy Hadoop warehouses.
Dremio and FlashBlade create a flexible and performant foundation for modern SQL analytics, powering BI and visualization tools like Apache Superset. Companies are already using the combined Dremio and FlashBlade platform for mission-critical analytics.
How to Configure Dremio and FlashBlade
Dremio leverages storage in two key ways: Data Lakes and the Distributed Store.
Data Lakes represent source data for Dremio to query and three different sources can query directly against FlashBlade: S3, NAS/NFS, and Hive/S3. These three options allow Dremio to query tables on FlashBlade stored either as objects or files, as well as share table definitions with legacy Hive services also using FlashBlade.
The Distributed Store location contains accelerator tables, job results, downloads, and upload data and can be configured to use an S3 bucket on FlashBlade.
The following section will describe how to configure and use the FlashBlade for all these data needs.
I leveraged the community Helm Chart to install Dremio v12.1.0 in Kubernetes. This helm chart also configures PersistentVolumes for different services, including ZooKeeper, Coordinator, and Executors, which can be automatically provisioned on a FlashArray™ for FlashBlade via the Pure Service Orchestrator™.
Running Dremio with FlashBlade requires Purity//FB 3.1.3 or newer.
Configure an S3 Data Lake Source
An S3 data lake connects to a FlashBlade S3 account to access tables on some or all buckets within that account. If data is stored on multiple FlashBlade devices, add each one as an additional Data Lake.
On the Dremio UI, choose “Add Data Lake” to add a new S3 data lake source.
From the choices, select “Amazon S3” to configure an S3-compatible data lake. As long as the backend S3 provider supports the AWS S3 API, it can be used as a data lake backend.
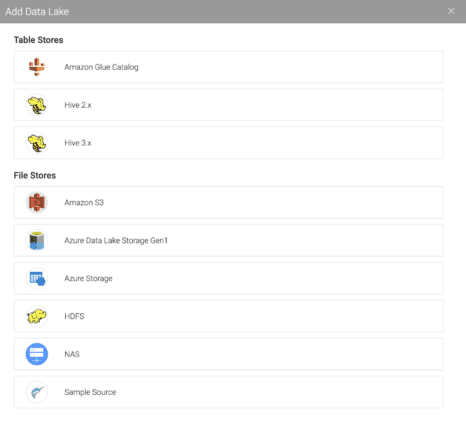
In the source configuration, give this data lake a descriptive name and copy-paste your access and secret key used for authorization.
The S3 access keys can be created via either the FlashBlade UI, CLI, or REST API. As an example, to create an S3 account and access keys via CLI:
pureuser@irp210-c01> pureobjaccount create dremio
pureuser@irp210-c01> pureobjuser create dremio/dremio-user
pureuser@irp210-c01> pureobjuser access-key create --user dremio/dremio-user
The returned secret key is only shown once so ensure that you write it down securely.
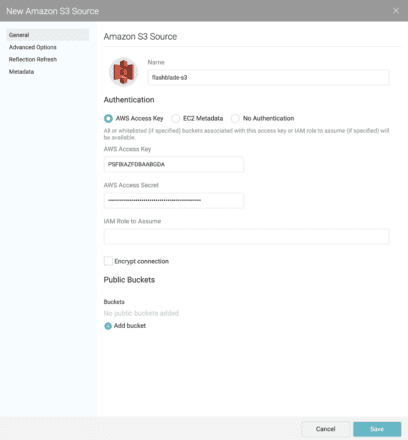
Before clicking “Save,” switch to the “Advanced Options” pane.
Then add three “Connection Properties”:
- fs.s3a.endpoint should point to the FlashBlade data VIP
- fs.s3a.path.style.access should be “true”
- fs.s3a.connection.ssl.enabled to “false.” You can enable SSL connections if you have imported a valid certificate into FlashBlade.
Finally, add the bucket names within the account that you wish to access to the “Whitelisted buckets” list.
Finally, click “Save” to finish the configuration of the S3 data lake.
Once created, navigate the folders in the data lake to identify the table locations you wish to use. Select the “Format Table” option on the right side in the screenshot below to import the table. For this example, I am selecting a table path that contains Parquet table files.
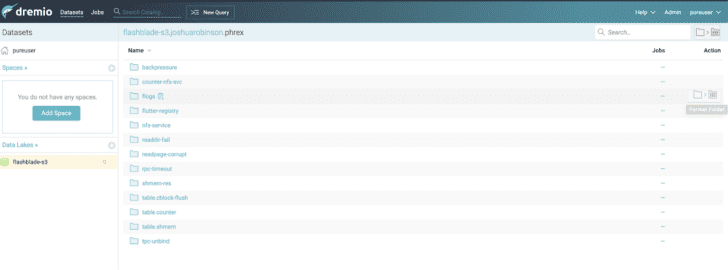
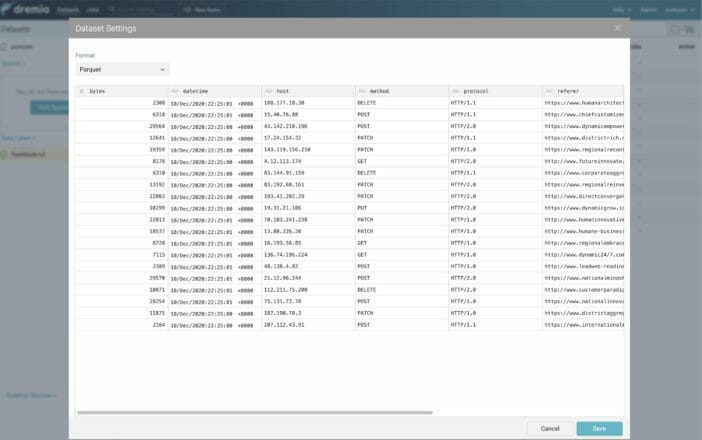
On the next screen, Dremio will detect the Parquet format and schema for the table. If all looks good, select “Save.”
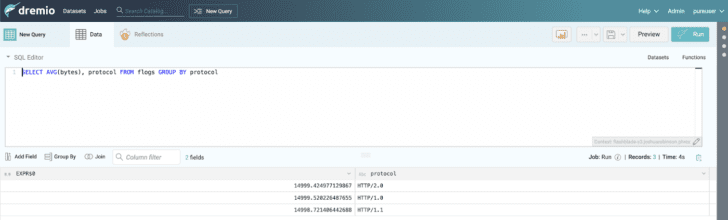
The Data Lake and table are now configured and Dremio can be used to run queries against the dataset using the SQL Editor built into the Dremio UI. The screenshot below shows an example query.
Configure a Filesystem Data Lake
A filesystem (NAS) Data Lake requires a remote filesystem like NFS available at a common mount point on each Dremio node.
In non-Kubernetes deployments, you simply follow the mounting instructions for the remote filesystem on each node and separately ensure that the mount is always available on all nodes. Fortunately, Kubernetes allows you to leverage CSI drivers and persistentVolumes to automate this process. When scaling out the Dremio cluster, Kubernetes automatically ensures the mount is available on new pods. The Dremio helm chart contains hooks to configure “extraVolumes” which will be automatically attached to all Dremio resources.
For data created outside of Kubernetes, import the existing filesystem in one of two ways: creating a volume of type NFS or as an imported PersistentVolume using the following PSO documentation. Once imported, you can use the associated persistentVolumeClaim as an extraVolume.
If the data is produced by a Kubernetes application, you can use a standard read-write-many (RWX) volume. The application, e.g., Apache Spark, writes to the RWX persistentVolume from which Dremio then reads.
Specify the extraVolume and corresponding extraVolumeMount in the values.local file when installing the Dremio helm chart. In the example below, I am adding two volumes: one leveraging an existing PVC called “irp210-pvc-import” and the second creating an NFS volume named “phonehome-data”:
# Extra Volumes
# Array to add extra volumes to all Dremio resources.
extraVolumes:
- name: irp210-data
persistentVolumeClaim:
claimName: irp210-pvc-import
- name: phonehome-data
nfs:
server: 10.61.204.100
path: /phonehome
# Extra Volume Mounts
# Array to add extra volume mounts to all Dremio resources, normally # used in conjunction with extraVolumes.
extraVolumeMounts:
- name: irp210-data
mountPath: “/datalake”
- name: phonehome-data
mountPath: “/phonehome”
After creation of the Dremio cluster, add a new NAS Data Lake in the Dremio UI by selecting “NAS” from amongst the “File Stores” choices, as shown in the screenshot below.
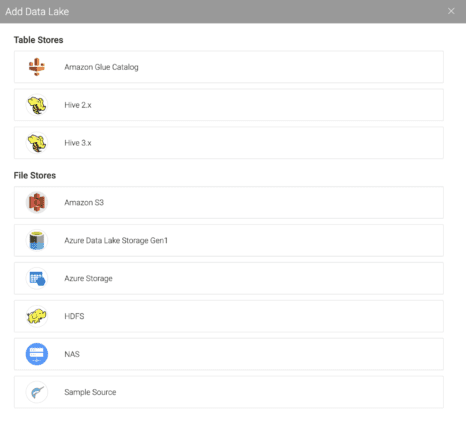
Then, for each NAS source, point the “Mount Path” to the location on each executor where the extraVolumeMount path was configured.
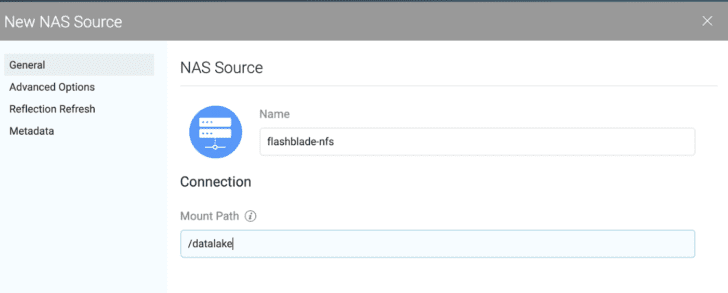
Once added, you can import individual tables and run queries with the same process as with an S3 source.
Configure a Hive Data Lake
You can also configure a Data Lake based on a Hive Metastore service. The Hive Metastore maintains table and partition information that can be shared with other query engines, like Hive or Presto. This mode only requires Dremio to interface with the Metastore for table metadata; all data path operations still use Dremio and not legacy Hive.
The advantage of a Hive source is the ability to easily share tables with legacy Hadoop and other services like SparkSQL or Presto/Trino. All these query engines can share the same underlying copy of data and stay in sync with each other’s view of the table definitions. This allows Hive to update a table, for example, adding a new partition, and have that automatically visible in Dremio. As a result, the Hive source enables sets of users to seamlessly move from Hive to Dremio without needing a disruptive all-at-once migration.
The disadvantage of a Hive source is the requirement to maintain two separate systems, i.e., the Hive Metastore service and backing database. Therefore, you should prefer the standard S3 source unless you need the synchronization a Hive source provides with other query engines.
To configure, select new “Hive 3.x Source” (or 2.x if using older systems) and enter the Metastore service hostname and port.

In the “Advanced Options” pane, we configure the necessary parameters to access the Hive Tables on FlashBlade S3.
Configure the following parameters:
- fs.s3a.endpoint should point to a FlashBlade data VIP
- fs.s3a.path.style.access set to true
- Optionally, set fs.s3a.connection.ssl.enabled to false if you have not imported a certificate to the FlashBlade
- fs.s3a.access.key to access key from FlashBlade
- fs.s3a.secret.key to secret key from FlashBlade
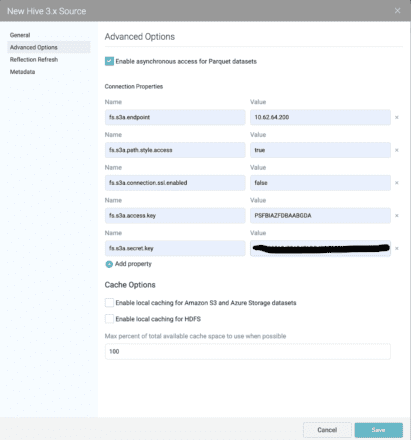
Once configured, the table definitions from the Hive Metastore service should automatically populate in Dremio.
Automating Data Lake Configurations
Dremio data sources can be configured in the UI as above or programmatically through the Dremio REST API. This allows users to automate adding sources without needing to redeploy the helm chart or restart services. Add new Data Lakes by leveraging the Catalog API and the source config details to configure a new data source.
Instead of interacting with the raw API endpoints, the Dremio Python client simplifies interacting with the Dremio REST API.
Filesystem or Object Store? Both
You can create multiple Data Lakes on the same FlashBlade, mixing NFS filesystems and S3 buckets, depending on where datasets live. This flexibility avoids requiring you to make an extra copy so that all data is in the same storage protocol and location.
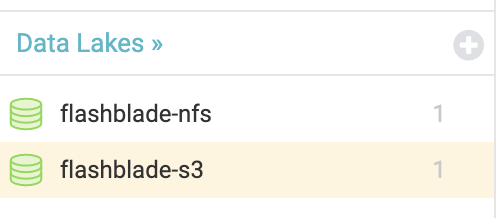
It is then trivial to write queries joining tables from different underlying data sources. As an example, see the following query that joins two TPC-DS tables, one on NFS and the other on S3:
SELECT cc.cc_class,
Sum(cs.cs_sales_price) AS “sales total”
FROM
“flashblade-s3”.joshuarobinson.”external_tpcds”.”catalog_sales” AS cs
INNER JOIN “flashblade-nfs”.”call_center” AS cc
ON cs.cs_call_center_sk = cc.cc_call_center_sk
GROUP BY cc.cc_class
Distributed Store on S3
The Distributed Store location contains accelerator tables and job results and can be configured to use a bucket on FlashBlade. By default, Dremio uses local storage and switching to an S3 bucket removes the need to provision and size the local node storage.
The yaml configuration for the Distributed Store is included in the “values.yaml” file given during helm installation. The lines that should be customized for your environment are highlighted in bold.
distStorage:
type: “aws”
aws:
>bucketName: “dremio”
path: “/”
authentication: “accessKeySecret”
credentials:
< >accessKey: “ACCESS”
secret: “SECRET”
extraProperties: |-
<property>
<name>fs.s3a.endpoint</name>
<value>10.62.64.200</value>
</property>
<property>
<name>fs.s3a.path.style.access</name>
<value>true</value>
</property>
<property>
<name>dremio.s3.compat</name>
<value>true</value>
</property>
<property>
<name>fs.s3a.connection.ssl.enabled</name>
<value>false</value>
</property>
<property>
<name>fs.s3a.aws.credentials.provider</name>
<value>org.apache.hadoop.fs.s3a.SimpleAWSCredentialsProvider</value>
</property>
Performance Testing
Dremio is capable of reading through large datasets at high speeds. I compare the performance of a simple Dremio query against a table on FlashBlade S3 versus the same table on AWS S3.
The test query averages columns from a 3.4TB CSV table, derived from the TPC-DS catalog_sales table. I test using Kubernetes 1.17.0, the Dremio helm chart, and open source Dremio version 12.1.0. Each Dremio executor uses 16 cores and 64GB of memory and tests were run on both platforms with between three and six total executors.
I use EKS to provision Kubernetes in AWS and m5d.8xlarge instances. The on-prem environment connected to FlashBlade has 40-core Xeon E5–2660 v3 CPUs (six-year-old gear) and 192GB of memory. In both platforms, the physical compute nodes are large enough for two Dremio executors per node, though I only test with one per node. Kubernetes resource limits enable creating pods of equivalent size across the two platforms.
I focus testing on CSV tables and a simple query in order to require the most performance from the underlying storage layer.
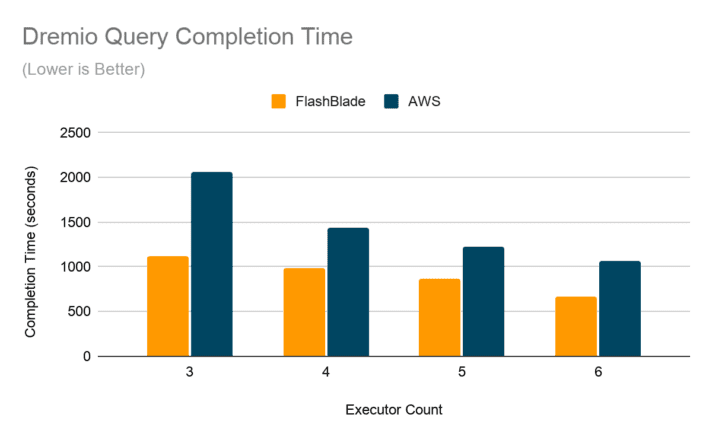
The graph above shows both linear scaling as executors increase and that the Dremio query against FlashBlade S3 is 60-70% faster than with AWS S3, though the variation in response times against AWS S3 varied significantly over multiple runs. For example, the fastest query time on AWS S3 was 40% lower than the slowest.
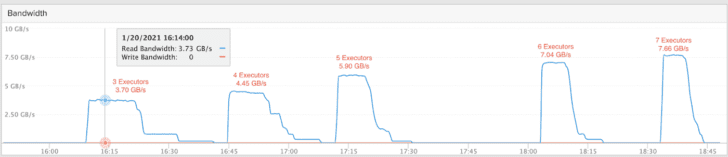
The screenshot shows the read performance from the FlashBlade UI perspective during each test run, plus an additional seventh run. To increase performance further, additional blades can be added to a FlashBlade for linear scaling.
Advancing the Lakehouse Stack with Dremio + FlashBlade//EXA
The ecosystem around modern SQL analytics has evolved significantly—and so have the capabilities of both Dremio and FlashBlade. If you’re building or scaling a lakehouse architecture today, this pairing is even more powerful.
On the Dremio side, recent innovations like Autonomous Reflections and Iceberg Table Clustering have drastically reduced the manual effort required to optimize query performance. Combined with support for Apache Polaris, Dremio’s unified catalog layer now enables fine-grained access control, lineage, and auditability across multi-cloud environments—critical for enterprise-grade data governance.
Meanwhile, FlashBlade//EXA has redefined what’s possible at the storage layer. With single-namespace throughput exceeding 10 TB/s and native support for concurrent high-performance and metadata-heavy workloads, FlashBlade//EXA delivers the low-latency, high-bandwidth foundation modern lakehouse engines demand. The architecture is inherently parallel and non-disruptive, which means analytics platforms like Dremio can scale out elastically without storage becoming a bottleneck.
Together, these advances make it possible to operationalize SQL analytics on data lakes at a scale and speed that simply wasn’t achievable a few years ago. This isn’t just about cost-effective analytics—it’s about enabling near real-time insight across petabyte-scale datasets with minimal architectural complexity.
If you’re already using Dremio and FlashBlade, the stack you chose has matured well. If you’re evaluating lakehouse patterns for SQL workloads in 2025, this combination is still best-in-class.
Conclusion
The scale-out performance and disaggregated architecture of Dremio and FlashBlade bring flexibility and agility to modern, on-prem SQL analytics. A key advantage is the ability to query data in place with both filesystems and object stores on the same FlashBlade. Avoiding extra data copies and ETLs simplifies workflows and frees up data engineers’ valuable time.
Further, the Hive data source enables Dremio to co-exist with legacy hadoop by sharing the same data and tables on FlashBlade S3. This configuration simplifies a modernization strategy by letting you migrate users from Hive to Dremio one at a time instead of forcing them all at once. FlashBlade as storage for Dremio enables modernizing an existing environment, as well as powering fast, scalable analytics on file and object datasets.

Applications and Databases
Simplify management, boost performance, and dramatically
cut costs




