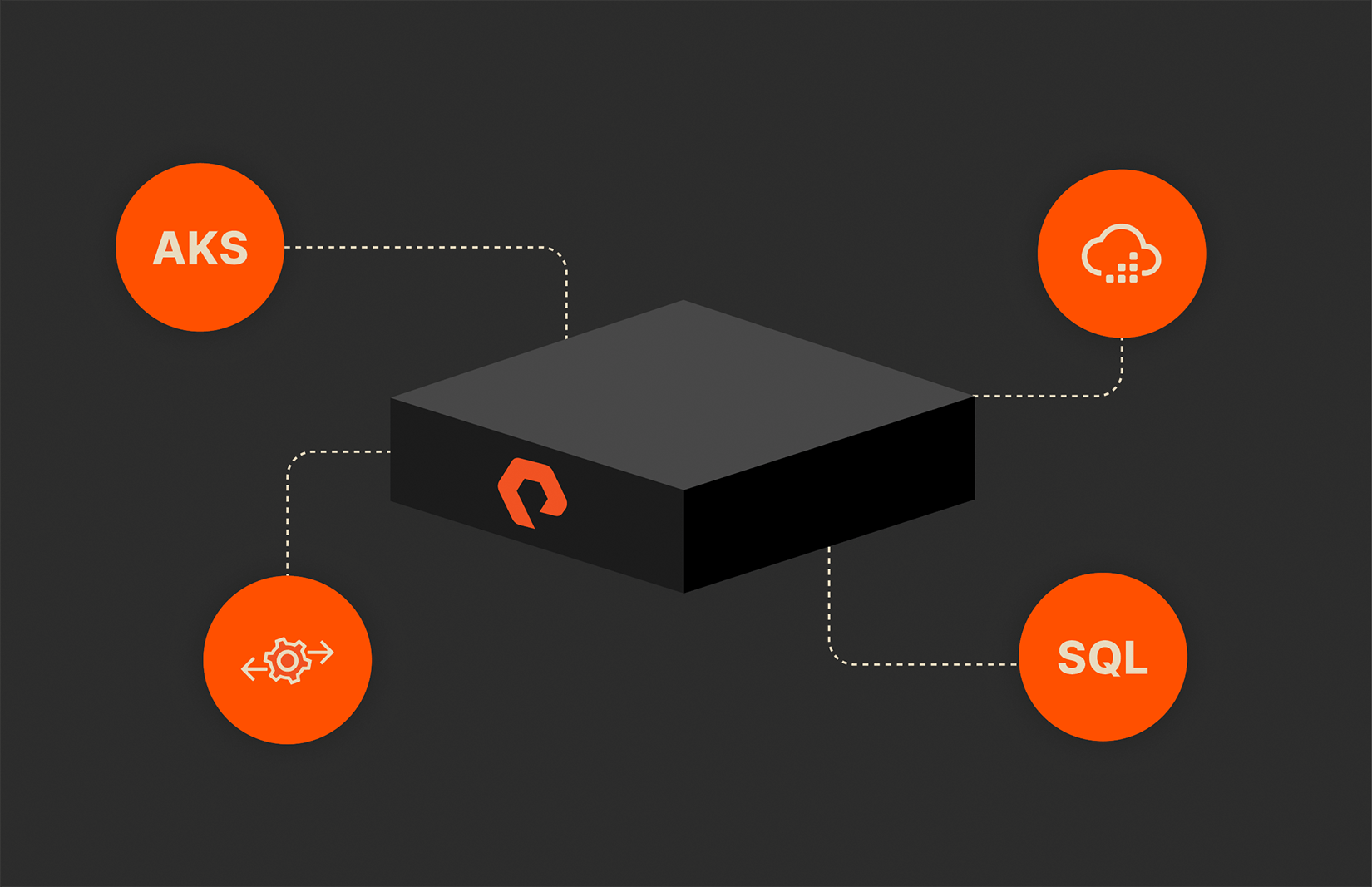


Let’s say you have a fairly sizable SQL Server database hosted in your on-premises data center. Being the savvy tech aficionado that you are, you likely have it containerized and running in your Kubernetes cluster. Now you want to leverage resources in the cloud to do some DevTest, but what about all that data?
With a solution from Pure Storage® and Microsoft, you can efficiently replicate your data to the cloud and take advantage of the cloud’s inherent scalability, which makes it a perfect target for DevTest. Here are the key components we’ll be using to build out this solution:

Let’s take a look at how it all fits together.
My lab has infrastructure that is likely pretty similar to your own, starting with a Kubernetes cluster with nodes that are virtual machines connected via iSCSI to a FlashArray//X90. The FlashArray™ has incredible performance, providing a high number of storage operations per second at the lowest possible latency—exactly what you’d want for a production database. Equally as important are the data services that come with it. Particularly, data-reduction technologies and asynchronous replication. As we’ll soon see, these features enable us to get data out of the data center and into the cloud as efficiently as possible. That data mobility is really the linchpin that enables this hybrid-cloud development and test scenario to work.
I’m completely amazed at how quickly you can stand up a new SQL Server instance with Kubernetes as you can see in the documentation. Though this tutorial is specific to Azure Kubernetes Services (AKS), you can use the same methodology to create a manifest file to deploy in your own Kubernetes cluster.
To run a containerized database, you’re going to want persistent storage. Whether you’re using a Pure Storage FlashBlade®, or a FlashArray in this scenario, persistent storage with Kubernetes is possible through Pure Service Orchestrator, a unified Container Storage Interface (CSI) driver. Pure Service Orchestrator allows for smart provisioning based on the performance, load, and health of your array. Elastic scaling makes adding new arrays incredibly simple, along with transparent recovery should issues arise—self-healing if you will.
For detailed information on Pure Service Orchestrator, including how to install it in your own environment, check out our GitHub page.
In the lab, we installed SQL Server, copied in a 500GB compressed backup file, and restored to a new database which was 1.7TB in size. We used Pure Service Orchestrator to mount a persistent volume at /var/opt/mssql within the container, which is where all of the data is stored. It looks something like this:
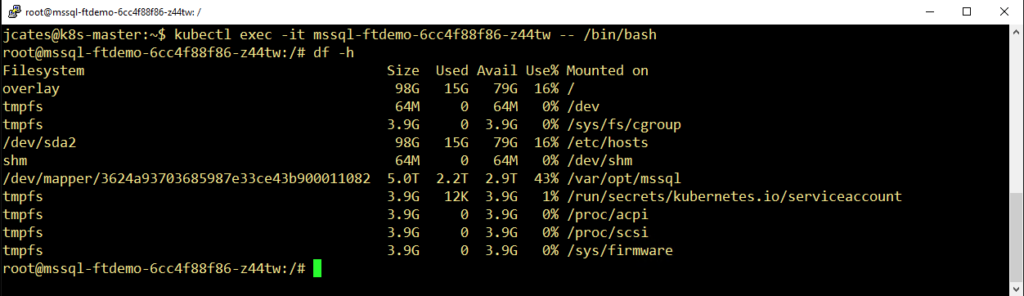
So now we’ve deployed our containerized SQL Server, connected it to persistent storage using Pure Service Orchestrator, and have a sizable amount of data residing in the database. Let’s get it to the cloud!
To make things super easy, we’ll deploy Pure Cloud Block Store (sign up for the beta on Azure Marketplace). In a few clicks, you’ll have an instance of the Purity Operating Environment running within Azure. Pure Cloud Block Store looks, feels, and acts exactly like running Purity on-premises, only rather than running on a FlashArray, it runs on top of cloud-native resources within Azure.
One important thing to note: When you deploy Pure Cloud Block Store—and AKS later—you’ll have the option to choose a subnet. Make sure you use the same subnet for both.
Because we’re running Purity, we can establish a replication relationship directly between our FlashArray and Pure Cloud Block Store. You’ll need to establish network connectivity to your Azure VNet first so that the on-premises FlashArray and the Pure Cloud Block Store can communicate. In our scenario, we configured a VPN. Once they can talk, we can establish Pure Cloud Block Store as a target array and replicate volume snapshots to it just as we would if it were another physical array.
The last piece of infrastructure we need to provision is AKS, which is a managed Kubernetes service from Microsoft that makes creating a Kubernetes cluster about as simple as can be. Compared to provisioning a DIY Kubernetes cluster, AKS is more like a vending machine. You put your money in and out comes a fully provisioned Kubernetes cluster minutes later. Use one of the fields within the deployment wizard to handle any customization you need. (Full disclosure: Since we’ll be connecting the AKS nodes to Pure Cloud Block Store via iSCSI, I did have to configure the iSCSI initiators on each of the nodes.)
At this point, the on-premises cluster is running SQL Server, the on-premises array is replicating directly into the cloud, and a freshly provisioned AKS Kubernetes cluster is in the cloud as well. Now it’s time to spin up some development and test instances.
In the demo, you’ll see that I created a few clone volumes from the replicated volume which contains the SQL database. I chose to do this part manually for this particular demonstration, though there are many options for automating this. Each of these clones is logically an independent version of the database, and changes made to any one of them will have no impact on the others. As a result, each developer can have their own version of the data without having to worry that actions they take during the development process might adversely affect other developers who are also using one of the clones. Not to mention, other than any new unique data which is written by the developer, each of these clones will consume no additional space. None. Nada. That’s one of the big reasons why you can provision them so quickly. Because there’s no physical data copy, it doesn’t matter if there’s a gigabyte of data or a terabyte; the clones will be available practically instantly.
Now that we’ve created the clones, we’ll combine the persistent volume claim, persistent volume, SQL Server container, and SQL service into a single manifest file.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 |
apiVersion: v1 kind: PersistentVolume metadata: annotations: pv.kubernetes.io/provisioned–by: pure–csi name: puresqlclone1 spec: accessModes: – ReadWriteOnce capacity: storage: 5Ti claimRef: apiVersion: v1 kind: PersistentVolumeClaim name: puresqlclone1–pvc namespace: default csi: driver: pure–csi volumeHandle: puresqlclone1 volumeAttributes: backend: block persistentVolumeReclaimPolicy: Delete storageClassName: pure–block volumeMode: Filesystem —– apiVersion: v1 kind: PersistentVolumeClaim metadata: name: puresqlclone1–pvc spec: accessModes: – ReadWriteOnce resources: requests: storage: 5Ti storageClassName: pure–block —– apiVersion: apps/v1 kind: Deployment metadata: name: mssql–pure–clone1 spec: replicas: 1 selector: matchLabels: app: mssql template: metadata: labels: app: mssql spec: terminationGracePeriodSeconds: 10 containers: – name: mssql image: mcr.microsoft.com/mssql/server:2017–latest ports: – containerPort: 1433 env: – name: MSSQL_PID value: “Developer” – name: ACCEPT_EULA value: “Y” – name: SA_PASSWORD valueFrom: secretKeyRef: name: mssql key: SA_PASSWORD volumeMounts: – name: puresqlclone1 mountPath: /var/opt/mssql volumes: – name: puresqlclone1 persistentVolumeClaim: claimName: puresqlclone1–pvc —– apiVersion: v1 kind: Service metadata: name: mssql–pure–clone1 spec: selector: app: mssql ports: – protocol: TCP port: 1433 targetPort: 1433 type: LoadBalancer |
Figure 4: The combined manifest.
Once the manifest is applied with the kubectl command, the cloned volume will be imported, the SQL Server container will be created, the cloned data will be present in /var/opt/mssql, and a service will be exposed so that we can communicate with the database. We can even group several of these manifests together in a single directory and create multiple development and test database instances at once with a single command.
Try it out for yourself and leave us a comment to let us know what you think.
Learn more about Pure Cloud Block Store and FlashArray.
Get access to the Pure Cloud Block Store for Azure beta from Azure Marketplace.

How Storage Plays a Role in Optimizing Database Environments
Tune in to Pure
Check Out the Latest Episodes



