本系列 第一部分 我們討論了如何利用 Red Hat OpenShift 在多重雲端環境(AWS 和 Azure)部署 Portworx。本次文章我們將會介紹 WordPress 應用程式部署以及利用 Portworx PX-DR 為應用程式執行故障轉移與故障回復作業。
在 Portworx 上部署 WordPress
Portworx 安裝完成後,接下來就是在叢集上部署 WordPress。本次解決方案我們利用 Portworx 以達到命名空間的複寫精細程度,第一步即是為 WordPress 創建全新的命名空間—我將其命名為 aws-azure-migrationnamespace。
命名空間建立完成後,即可在此安裝 WordPress,請按此處查看我們提供的說明。
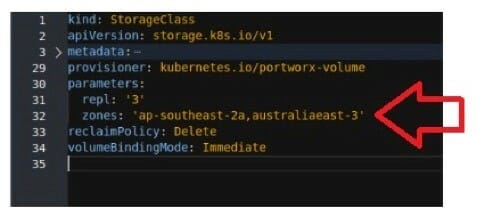
知識小站 #1:為了確保複寫妥善分配至兩個區域,我在 StorageClass 新增了 區域 的建置參數,雙區以 AWS 和 Azure 區域命名。
WordPress 一經安裝,便應檢查複寫:
- 使用下列指令來收集 aws-azure-migrationnamespace 內的持久性容量請求名稱(Persistent Volume Claim names):
oc get pvc -n aws-azure-migrationnamespace -o custom-columns=:.spec.volumeName
- 使用下列指令來收集 kube-systeme 命名空間內的 PX-叢集容量位元名稱:
oc get pods -n kube-system | grep px-cluster
- 若要定位支援各項 PVC 的 Portworx 容量 ID,可透過執行 /opt/pwx/bin/pxctl 容量清單 指令在各項 PVC 名稱內進行匹配搜尋。
oc exec pods/px-cluster-83716c65-bbb2-45ee-bae9-dc0cb39bdf07-668p6 -n kube-system /opt/pwx/bin/pxctl volume list | grep pvc-561a2c0d-3ece-4f13-b429-c3225caa7e06
- 最後,使用下指令檢閱容量 ID 建置:
oc exec pods/px-cluster-83716c65-bbb2-45ee-bae9-dc0cb39bdf07-668p6 -n kube-system /opt/pwx/bin/pxctl volume inspect 1116088806860818343
注意:有發現複寫如何分佈在兩處位址嗎? 這便是依拓撲性質進行複寫正在發生作用!
知識小站 #2:不需要為每一個應用程式創建 Portworx StorageClass,為各類應用程式創建 StorageClass 即可 – 舉例而言:
- Tier 1 非共享 StorageClass – 複寫因素 3、重要優先項目 IO、單一讀寫次數容量
- Tier 1 共享 StorageClass – 複寫因素 3、重要優先項目 IO、多讀寫次數容量
- Tier 2 非共享 StorageClass – 複寫因素 3、中度優先項目 IO、單一讀寫次數容量
- Tier 2 共享 StorageClass – 複寫因素 3、中度優先項目 IO、多讀寫次數容量
- Tier 3 非共享 StorageClass – 複寫因素 2、低度優先項目 IO、單一讀寫次數容量
- Tier 3 共享 StorageClass – 複寫因素 2、低度優先項目 IO、多讀寫次數容量
為 WordPress 外接代理 / 負載平衡器
在上述的 WordPress 部署中,應用程式透過節點 TCP 埠號 30303 的 NodePort 服務連接至網路。由於這項解決方案使用的是外部的負載平衡器/代理,因此每一個工作節點的 TCP 埠號 30303 都需要由外部代理連接以處理 Heartbeat 等請求。為完成任務,我為每一個 OpenShift 工作節點建置了公有的 IP 位址,然後新增存取控制串列 (ACL) 條目以允許代理伺服器/服務 IP 位址流量進入位於 TCP 30303 上的各個工作節點公有 IP 位址。
建置 STORK 以複寫 Kubernetes 物件
一旦應用程式的持久性資料在兩處位址都複寫完成,便可進行至解決方案的最終階段:使用 STORK 複寫 Kubernetes 物件。Portworx 說明書為同步環境中的 STORK 與 PX-DR 整合提供清晰明確的指導。說明指南 請按此處查看。
必要步驟為:
- 安裝 storkctl 命令列工具
- 配對叢集 – 此處可查看我的叢集配對 yaml 副本
apiVersion: stork.libopenstorage.org/v1alpha1kind: ClusterPairmetadata: creationTimestamp: null name: awsazurecluster namespace: aws-azure-migrationnamespacespec: config: clusters: ocazure: LocationOfOrigin: /root/.kube/config certificate-authority-data: {my CA certificate} contexts: admin: LocationOfOrigin: /root/.kube/config cluster: ocazure user: admin current-context: admin preferences: {} users: admin: LocationOfOrigin: /root/.kube/config client-certificate-data: {my client certificate} options: ip: “{ip of DR site Portworx node}” port: “17001” token: “{my token}” mode: DisasterRecoverystatus: remoteStorageId: “” schedulerStatus: “” storageStatus: “”
注意:OpenShift 上的 Portworx 使用 TCP 埠號 17001 – 17020 (與其他使用 9001-9020 的平台相反),因此需要通知 Portworx 應透過 TCP 埠號 (17001) 聯繫遠端叢集的 PX/OpenShift。在 ClusterPair yaml 檔案(參見上述)的 選項 區塊進行更動,即可完成。
- 建置搬移排程 – 此處可查看我所使用的搬移排程:
apiVersion: stork.libopenstorage.org/v1alpha1kind: MigrationSchedulemetadata: name: aws-azure-migrationnamespace-schedule namespace: aws-azure-migrationnamespacespec: template: spec: clusterPair: awsazurecluster includeResources: true includeVolumes: false purgeDeletedResources: true startApplications: false namespaces: – aws-azure-migrationnamespace schedulePolicyName: aws-azure-migrationnamespace-schedule
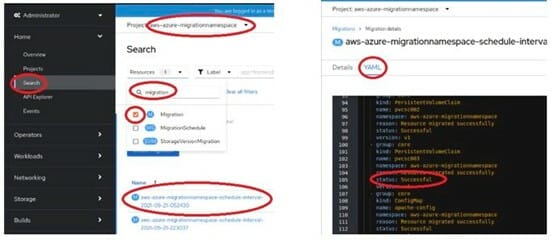
- 使用 Openshift GUI 或透過 Openshift 指令列監控複寫
oc describe migrations -n aws-azure-migrationnamespace
知識小站 #3:為了將生產叢集中的 STORK 寫入災害復原叢集中的 Kubernetes 物件,必須要能讀取遠端區域 Kubernetes API 服務的 DNS 名稱。 可至第一部分查看例行工作、DNS 和 ACL 區塊中的做法。
- 寫入故障轉移和故障回復的程式語言。 為了協助你的工作進行,此處包含了我所使用的故障轉移和故障回復程式語言:
故障轉移工作負載 – AWS 至 Azure
#!/bin/bash# Failover script executes from the Master Server on AWS OpenShift ClusterLOGFILE=”/tmp/portworx-failover-$(date +”%Y_%m_%d_%I_%M_%p”).log”echo “Logging output to $LOGFILE”# Run this on the destination clusterecho “Deactivating AWS cluster”ssh core@ocazure-k8s-master “sudo /usr/local/bin/storkctl deactivate clusterdomain ocaws” >>$LOGFILE 2>&1ssh core@ocazure-k8s-master “sudo /usr/local/bin/storkctl get clusterdomainsstatus” >>$LOGFILE 2>&1 # Scale down the replicasecho “Scaling pods down to 0 in AWS cluster”kubectl scale –replicas 0 deployment/wordpress -n aws-azure-migrationnamespace >>$LOGFILE 2>&1kubectl scale –replicas 0 deployment/wordpress-mysql-ha -n aws-azure-migrationnamespace >>$LOGFILE 2>&1 # stop the migration of the kubernetes objects so they don’t get overwritten on the targetecho “Stopping the STORK migration of objects”kubectl apply -f failover-application-suspend-schedule.yaml -n aws-azure-migrationnamespace >>$LOGFILE 2>&1storkctl get migrationschedule -n aws-azure-migrationnamespace >>$LOGFILE 2>&1 # start the application on the destination clusterecho “Scaling up the pods on Azure cluster”ssh core@ocazure-k8s-master “sudo kubectl scale –replicas 1 deployment/wordpress-mysql-ha -n aws-azure-migrationnamespace” >>$LOGFILE 2>&1ssh core@ocazure-k8s-master “sudo kubectl scale –replicas 3 deployment/wordpress -n aws-azure-migrationnamespace ” >>$LOGFILE 2>&1
failover-application-suspend-schedule.yaml
apiVersion: stork.libopenstorage.org/v1alpha1kind: MigrationSchedulemetadata: name: aws-azure-migrationnamespace-schedule namespace: aws-azure-migrationnamespacespec: template: spec: clusterPair: awsazurecluster includeResources: true startApplications: false includeVolumes: false purgeDeletedResources: true namespaces: – aws-azure-migrationnamespace schedulePolicyName: aws-azure-migrationnamespace-schedule suspend: true
故障回復工作負載 – Azure 至 AWS
#!/bin/bash# Failback script executes from the Master Server on AWS OpenShift ClusterLOGFILE=”/tmp/portworx-failback-$(date +”%Y_%m_%d_%I_%M_%p”).log”echo “Logging output to $LOGFILE” # activate the AWS cluster domainecho “Activating ocaws clusterdomain”ssh core@ocazure-k8s-master “sudo /usr/local/bin/storkctl activate clusterdomain ocaws” >>$LOGFILE 2>&1 # get the cluster statusecho “Getting ClusterDomain status”ssh core@ocazure-k8s-master “sudo /usr/local/bin/storkctl get clusterdomainsstatus” >>$LOGFILE 2>&1 # stop the applications on the clusterecho “Scaling Azure pods to 0″ssh core@ocazure-k8s-master “sudo kubectl scale –replicas 0 deployment/wordpress -n aws-azure-migrationnamespace” >>$LOGFILE 2>&1ssh core@ocazure-k8s-master “sudo kubectl scale –replicas 0 deployment/wordpress-mysql-ha -n aws-azure-migrationnamespace” >>$LOGFILE 2>&1 # scale up the pods on the source clusterecho “Scaling up pods in AWS Cluster”kubectl scale –replicas 1 deployment/wordpress-mysql-ha -n aws-azure-migrationnamespace >>$LOGFILE 2>&1kubectl scale –replicas 3 deployment/wordpress -n aws-azure-migrationnamespace >>$LOGFILE 2>&1 # re-enable the scheduleecho “Re-enabling STORK replication of objects”kubectl apply -f failback-application-resume-schedule.yaml -n aws-azure-migrationnamespace >>$LOGFILE 2>&1
failback-application-resume-schedule.yaml
apiVersion: stork.libopenstorage.org/v1alpha1kind: MigrationSchedulemetadata: name: aws-azure-migrationnamespace-schedule namespace: aws-azure-migrationnamespacespec: template: spec: clusterPair: awsazurecluster includeResources: true startApplications: false includeVolumes: false purgeDeletedResources: true namespaces: – aws-azure-migrationnamespace schedulePolicyName: aws-azure-migrationnamespace-schedule suspend: false
前端應用程式故障轉移
解決方案的平台部分完成後,便可以思考如何為前端客戶提供完美流暢的使用體驗。架構橫向擴充(及故障復原)模式時,雲端原生應用程式位於單一雲端,僅需供應一件雲端負載平衡器。但在兩個雲端之間運行的應用程式若要達成流暢體驗,便需要使用位於兩處雲端外部的負載平衡器。我的解決方案測試以下兩種不同方法皆可成功:
- 位於獨立位址的 NGINX 反向代理伺服器可以運用 Heartbeat 功能快取並代理應用程式,且能監控故障轉移(以及故障復原)。 你可在此處找到我所使用的骨架/非最佳化 NGINX 建置:
worker_processes 1;events { worker_connections 1024;}http { proxy_cache_path /nginx-cache/ levels=1:2 keys_zone=STATIC:100m inactive=1h max_size=1g; upstream puremite.karaka.nz { server (aws server public IP #1):30304 fail_timeout=3s ; server (aws server public IP #2):30304 fail_timeout=3s ; server (aws server public IP #3):30304 fail_timeout=3s ; server (azure server public IP #1):30304 fail_timeout=3s; server (azure server public IP #2):30304 fail_timeout=3s; server (azure server public IP #3):30304 fail_timeout=3s; } server { listen 80; server_name puremite.karaka.nz; location / { proxy_set_header Host $host; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $remote_addr; proxy_pass https://puremite.karaka.nz; proxy_cache STATIC; proxy_cache_valid any 5m; proxy_cache_use_stale error timeout invalid_header updating http_500 http_502 http_503 http_504; } }}
- 使用 Heartbeat 功能以快取、反向代理應用程式及監控故障轉移(以及故障復原)的第三方服務。
大體而言,我發現 Portworx 能夠相當快速地進行故障轉移和故障回復,但靜態網頁的故障轉移透過前端代理的額外快取即可順利修正。
知識小站 #4:為了最佳化負載平衡器的 Heartbeat 作業,我在 WordPress 的檔案根目錄創建了小型的 ‘Hello World’ PHP 語法,並依兩種方式的 Heartbeat 流程建置為目標 URL。 在生產過程中,Heartbeat 的目標 URL 可能不完全靜態而更具應用程式思維。
示範演練
我花了相當多篇幅描述自己的專案,但你也許想要看看實際應用的狀況?請參見這部影片,了解完整的解決方案執行過程。
影片播放器
00:00 – 02:46
總結
坦白說,早些時候我總懷疑 Kubernetes 是否還會發展下去,但隨著時間過去,我已臣服於它專注於應用程式的卓越功能:高可用性、擴充、產品生命週期與跨平台的可攜性。Kubernetes 為企業提供了強大的平台,可為任何雲端環境、任何規模加速創建雲端原生應用程式。
在專案啟動之始,我有四點問題有待解答:
- Kubernetes 工作負載理應為可攜式,但應用程式是否能橫跨兩個平台,像是兩個公有雲之間、或是私有雲與公有雲之間,真正達成可攜性?
- 若 Kubernetes 成為狀態應述應用程式的可能方案,那麼該如何為這些應用程式提供災難復原?
- 提供應用程式可攜性與災難復原應使用哪些工具?
- 既然工作環境為完全獨立運作,那麼該如何規劃故障轉移?
所有問題都清楚指向同一個解答:
- 有了 Kubernetes 和 Portworx,應用程式便可在不同位址、雲端與平台之間攜帶移動。
- 有了 Kubernetes 和 Portworx,我們便可為關鍵工作負載設計卓越的災難復原解決方案。
- Red Hat OpenShift 和 Portworx 是廣泛應用於這類案例的工具,證實有效。
- 處理故障轉移的方式與雲端原生應用程式的自動擴充相同:透過負載平衡器。
Red Hat OpenShift 評估
有了 Red Hat OpenShift,在檢閱安裝指南階段即可清晰明白它將推動企業採用 Kubernetes 工作環境。它相當易於安裝、整合與管理,並且有穩固的發布管理、安全性與客戶期望 Red Hat 提供的企業級支援。雖然這次專案應用到 OpenShift 的部分較少,但我往後勢必會再用到 OpenShift,很期待接下來一年能更多加應用。
Portworx 評估
至於 Portworx,很少有產品能與它比肩,深深吸引我注意。我相當欣賞其設計,且仔細推究原理會發現,它能供應客戶持續提升產品價值。我認為,對於需要大規模運行容器環境的客戶而言,Portworx 不可或缺。若你還未試用過 Portworx,請給自己一次機會。你可下載 免費試用版 或 與 Portworx 排定會議 了解更多內容。
重要提問:你應該使用這些產品嗎?
如果你希望從我的專案學到一些東西,那就是 Kubernetes、Portworx 和 Red Hat OpenShift 皆為威力強大的技術,不論位址為何都能夠推動資料移動性。有了資料移動性,選擇和彈性也隨之提升,這對於步調快速的技術產業界在擬定 IT 策略時十分重要。
當你在考慮兩處不同公有雲的正式環境與災難復原作業時,有許多重點需要注意與管理,像是網路輸出費用和公有雲邊緣停電問題,可能會排除掉合適的跨雲端災難復原解決方案。 然而,一個包含了就地部署資料中心和公有雲資料中心的基礎架構也相當值得考慮。這樣的架構可能提供兩種環境最佳功能配置,兼顧了本地資料的效能與成本特性,又具備公有雲的絕佳彈性,只需最少量的網路輸出費用,而且在故障狀況發生時可將資料搬移至別處,從而保有適應力。