Today, we are further advancing on that vision and we are introducing breakthrough innovation in artificial intelligence that will enable the next level of reliability, simplicity, and efficiency.
In this blog I will share how we view the journey to self-driving storage, the steps that we have taken so far, and how our new innovations in machine learning uniquely position us to deliver self-driving storage.
Read more below and be sure to check our other blogs as part of this series.
Cloud-Era Flash: “The Year of Software” Launch Blog Series
- The Biggest Software Launch in Pure’s History
- Purity ActiveCluster – Simple Stretch Clustering for All
- FlashBlade – Now 5X Bigger, 5X Faster
- Fast Object Storage on FlashBlade
- Purity CloudSnap – Delivering Native Public Cloud Integration for Purity
- Simplifying VMware VVols – Storage Designed for Your Cloud
- Purity Run – Opening FlashArray to run YOUR VMs & Containers
- Extending our NVMe Leadership: Introducing DirectFlash Shelf and Previewing NVMe/F
- Windows File Services for FlashArray: Adding Full SMB & NFS to FlashArray
- Introducing Pure1 META: Pure’s AI Platform to enable Self-Driving Storage (THIS BLOG)
—
In the near future, self-driving cars will have a transformational impact in our lives and it is exciting to see how this technology evolves from limited use to full autonomy and mass adoption. Self-driving cars will take some time to be fully developed and adopted but there are some basic principles that are driving this technology:
- Automate & Simplify: Self-driving cars automate and regulate internal functions.
- Sense & model the world around: Self-driving cars leverage many sensors and cameras not only for guidance and navigation purposes but also for safety mechanisms as the cars interact with other cars, pedestrians, and environmental elements.
- Constantly learn & re-train: Self-driving cars use artificial intelligence to learn from the data that they collect. As these cars are exposed to more driving conditions, the better that they will be able to navigate and re-training allows correction of decision making models.
- Global effect: Self-driving car technology is more powerful if it can incorporate network intelligence rather than just individual car insights. Next level efficiencies such as traffic optimization can only be achieved with a global and network view across cars.

With this in mind, we think that there are very clear similarities between self-driving cars and self-driving storage. Just like self-driving cars, self-driving storage requires the elimination of manual operations. Sensing and being able to model the environment is critical to understanding an evolving IT landscape and the data used to create models must also be representative of all customer environments. With many different applications in consolidated environments, the results can be unpredictable. So, self-driving storage must also provide a level of protection and safety to accommodate all the interacting elements. Finally, self-driving storage must also extend beyond single array optimization and deliver global intelligence.

Since founding Pure, our mindset was to remove knobs and dials and automate underneath so we can eliminate as much of the admin pain as possible. Purity delivers this level of automation and simplicity. As a Pure customer, there isn’t much to do after you plug in the array.
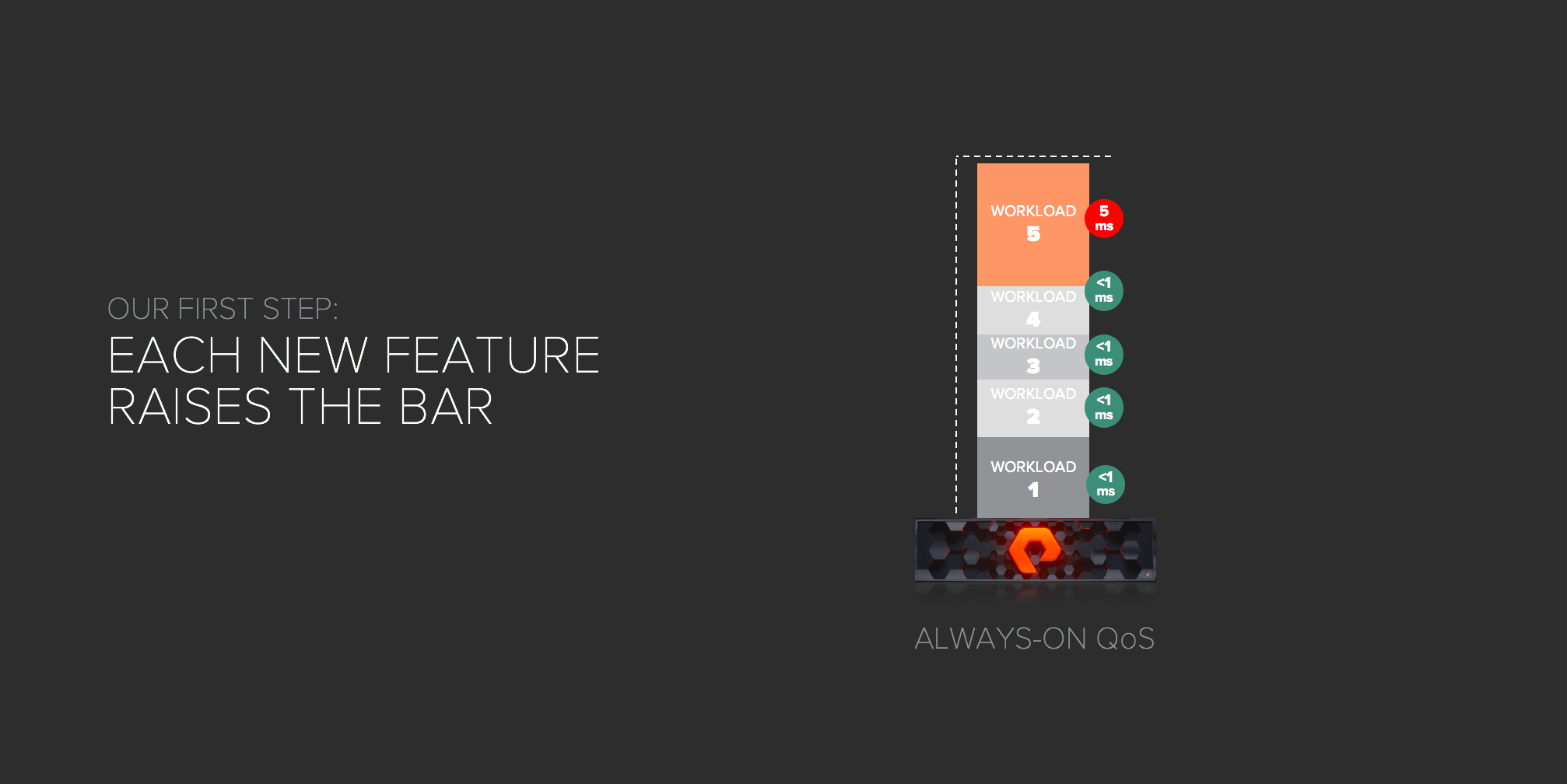
 With new Purity features that we introduce, we continue to make the storage experience simpler. For example, when we introduced Always-On QoS, we delivered automatic protection of system workloads against another workload that could consume all system resources and impacting all tenants.
With new Purity features that we introduce, we continue to make the storage experience simpler. For example, when we introduced Always-On QoS, we delivered automatic protection of system workloads against another workload that could consume all system resources and impacting all tenants.
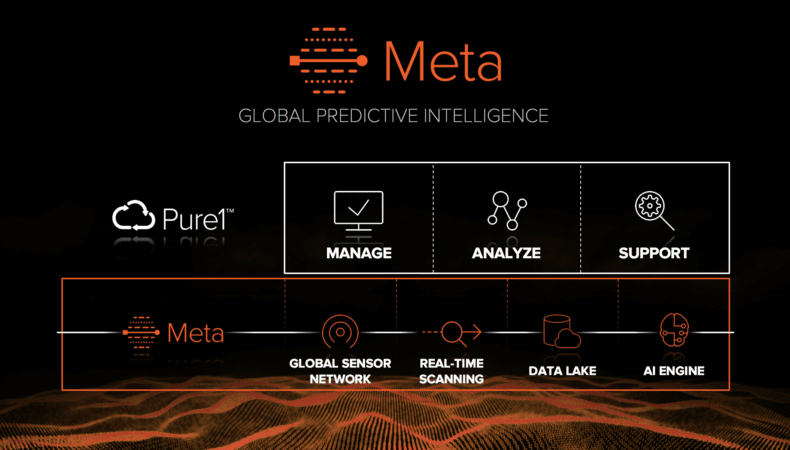
Pure1® is a key element in our vision to deliver self-driving storage and it has a massive global sensor network. We have thousands of arrays deployed globally and we’re now collecting over trillion telemetry data points per day. This rich data holds great potential and there are many interesting ways we can leverage it.

First, we make it directly visible for customers so they can see globally what’s going on with their arrays. Customers can access Pure1 from anywhere, with any device, and with the new Pure1 Global Dashboard, they can view a summary of total capacity, performance, data reduction and other metrics across their entire fleet.

The data collected from the global sensor network is also fundamental to our predictive support. Similar to how virus scanners work, we fingerprint all issues and search for those issues in real time across all the arrays. We’ve avoided >500 Sev1 issues to date with this technology, and we continue to make it smarter, day by day. Pure1 support is 24/7 and predictive, and we find and fix most issues before our customers are even aware of them. All of this works together to deliver our measured six nines of availability – inclusive of maintenance and even generational upgrades.

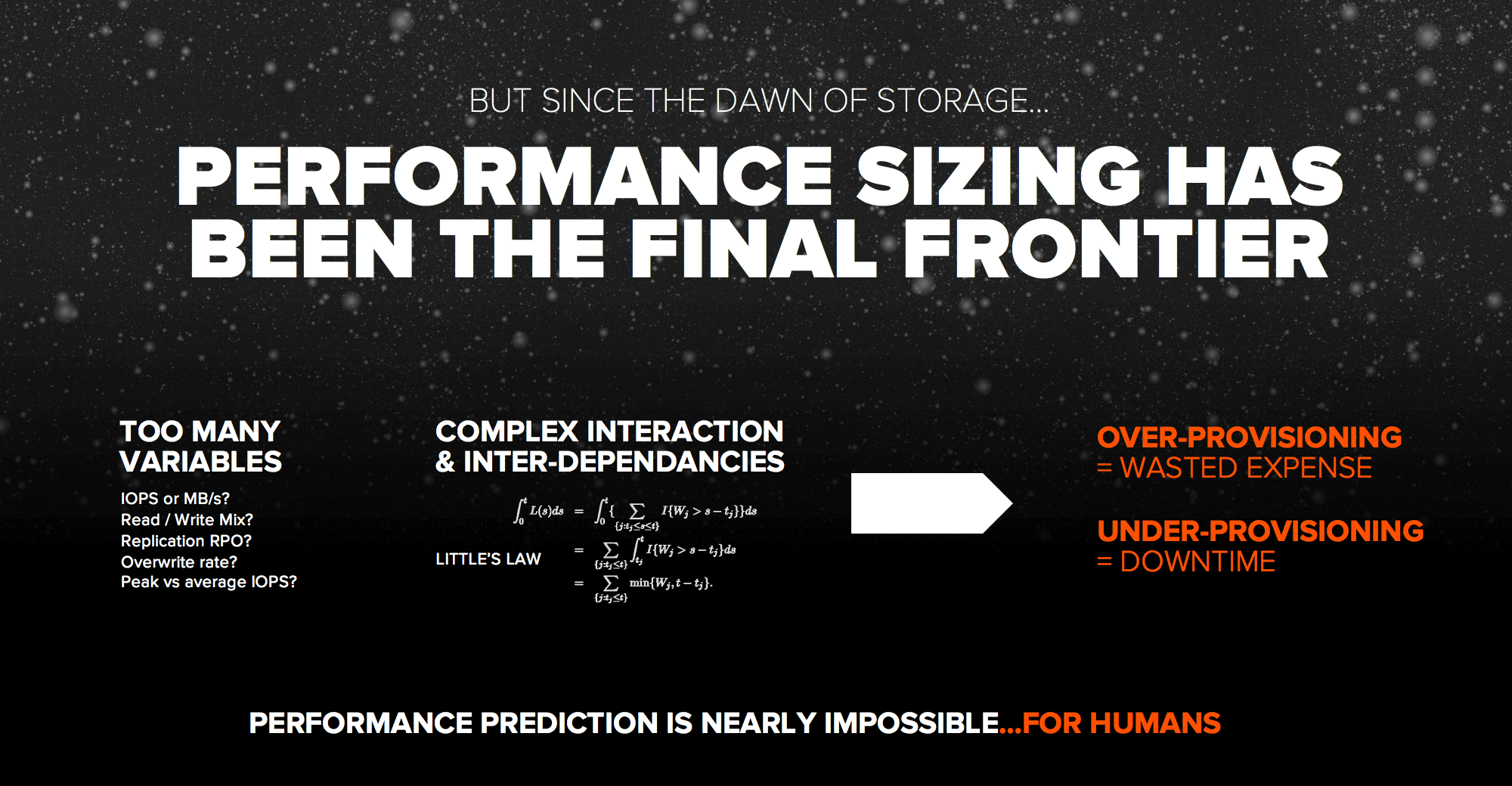
However, for many years, performance sizing has been incredibly challenging as there’s a ton of variables and there’s a lot of complex interactions and interdependencies. Two workloads might perform well on separate arrays but when they’re on the same array they can interact in unpredictable ways. The net result is you have one of two bad things happen: you either end up way over-provisioning, which is the more common thing when people buy arrays way bigger than they need, or you under-provision and that causes performance issues and eventually downtime. It turns out trying to understand performance and do complex math to size arrays is nearly impossible – at least for humans.
We saw a huge opportunity here to use advanced AI techniques to approach this problem in a fundamentally new way and today we are excited to introduce Pure1 META, our global intelligence engine within Pure1.

META is going to be used in many ways over time, but the first thing it’s going to be used for is to understand workload. To do this we created a machine learning model to characterize these workloads, and we call this model Workload DNA.

Today, our arrays measure over a thousand different performance indicators, so the first thing we had to do was ask which set of these actually matter to predict performance of a given workload. And different workloads can have different sets of best predictors. Because we have over 100,000 workloads in our global network now, we used computers to figure this out using machine learning. And we innovated to normalize the results so we can make direct performance comparisons across completely different types of workloads – in other words workloads with very different DNA.
With META and workload DNA we can begin to answer some very challenging and valuable questions. The most obvious is – will a new workload fit? Workloads A & B are on the array, and I want to add workload C – will it fit on the array? Next, will A & B interact well? And how will the performance & capacity change and grow over time? We can also begin to understand how workloads evolve. For example, we can look at EPIC (one of the main electronic health records in use at U.S. healthcare organizations) across our network and as its DNA changes, we can inform our model. We can apply this intelligence across workloads run by our customers including Oracle, SAP, Microsoft SQL Server, and many more.
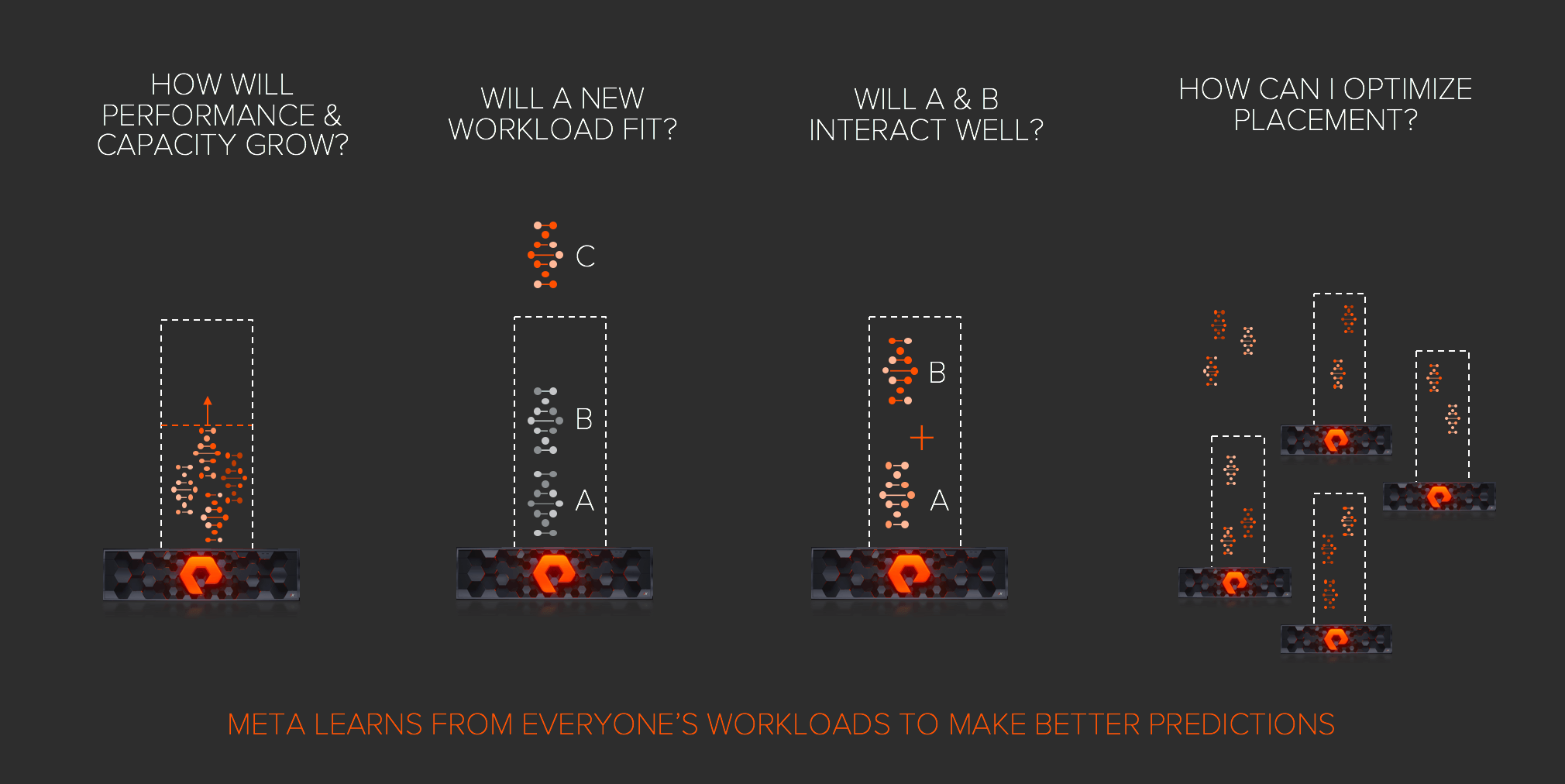
Customers can effortlessly take advantage of META and Workload DNA via our new Pure1 META Workload Planner. Easily move a slider and get a prediction on performance load or capacity. Deceptively simple but the magic is happening underneath it all.

Pure1 META Workload Planner is just the start, and our vision is to pair META with Purity ActiveCluster and Purity QoS, so we can also take workload placement and optimization to a new level. We’re developing ways to give administrators advice on which workloads are best co-located or placed on different arrays. And with ActiveCluster active-active stretch clustering, we can even affect the movement of workloads non-disruptively between arrays in the data center – or even across metro distances. The real exciting thing here is this is bridging the intelligence beyond a single array, learning from 100,000+ workloads, so every customer can have better insight into their workloads.
Over time, we expect META will further enhance our predictive support capabilities. Today our team of support engineers manually create fingerprints, but with META, we’ll be able to auto-generate machine-learning based fingerprints. And as we expand our global sensor network, META will be able to generate fingerprints not just for storage, but for the broader datacenter and application environment.
As we continue to make progress on our vision of self-driving storage, Pure1 META will be key to unlocking the next level of reliability and providing improved efficiency thru better sizing, and more intelligence about workload behavior.