
愛犬家のための AI を例に、FlashBlade で構築するエンドツーエンドの AI パイプラインをご紹介するブログシリーズ。第 1 回ではアーキテクチャの概要を、第 2 回ではリアルタイムなデータの取得、処理、視覚化がいかに容易にできるかをご説明しました。今回は、実際に FlashBlade と Apache Spark、Zeppelin、Apache Hive を使用したビッグデータ分析について解説します。
ビッグデータ分析の設定手順の概要
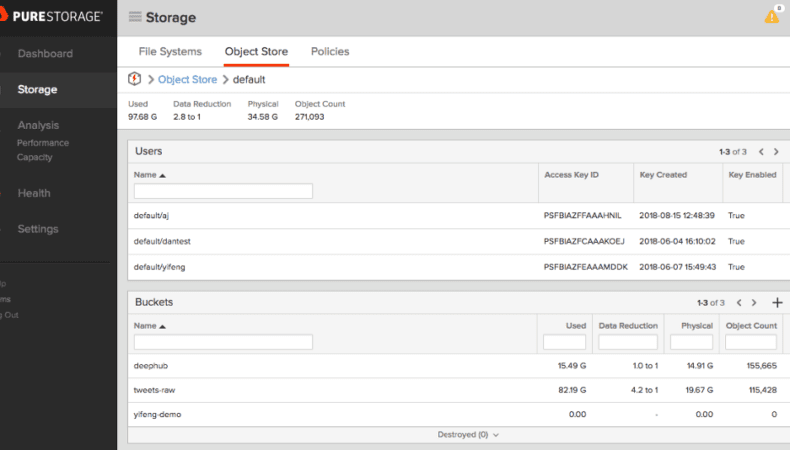
ビッグデータ分析を開始するにあたり、長期にわたって詳細な分析を行うために、ツイートのローデータを保持しておきたいと思います。それには、ビッグデータを FlashBlade S3 バケットに格納し、Spark と Zeppelin を使用して S3 のデータに直接アクセスして処理します。データ駆動型のインタラクティブなデータ分析とコラボレーションを可能にするために、Webベースのノートブック Zeppelin に Spark コードを入力します。Hadoop などの従来のビッグデータシステムとは異なり、ユーザーデータに Hadoop HDFS は使用しません。その代わりに、シンプルかつスケーラブルで、クラウドサービスとの統合が容易な S3 を使用します。これによって、コンピューティングとストレージを個別に拡張するための俊敏性と柔軟性も得ることができます。
ツイートのローデータを保存
Apache NiFi フローで取得した生の Twitter レスポンスレコードを 100 個ごとに 1 つの JSON ファイルにマージし、それを FlashBlade S3 バケットに送信します。PutS3Object プロセッサを使用すると、FlashBlad eへのデータ取得が非常に簡単になります。FlashBlade UI で S3 バケットを作成し、FlashBlade VIP をエンドポイント URL と自分のバケットとして使用するように PutS3Object プロセッサを設定します。
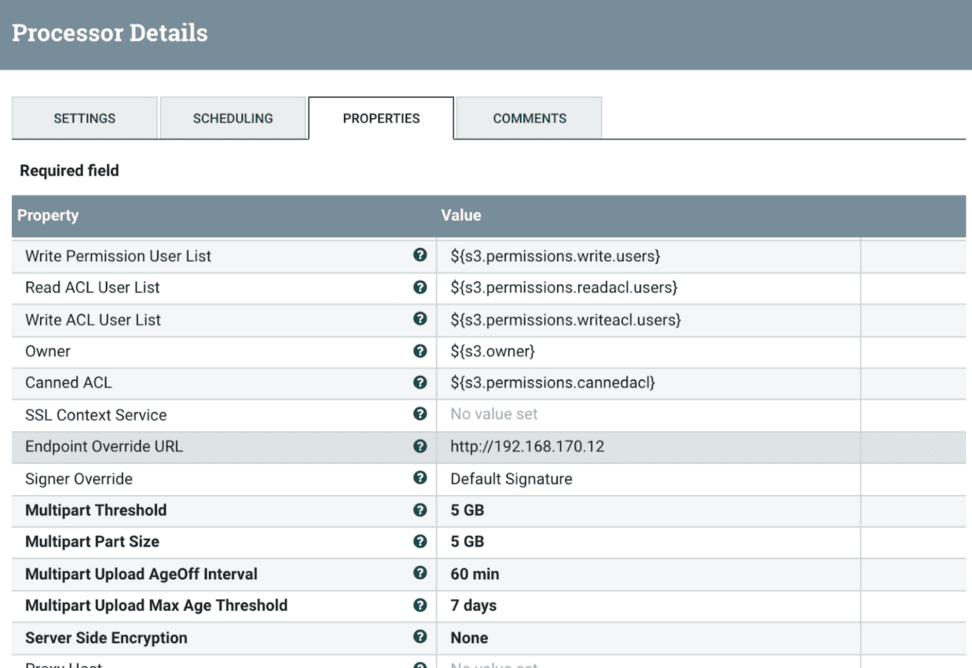
S3A の設定
Twitter のデータを FlashBlade S3 バケットに取り込んだ後は、Spark などのオープンソースのビッグデータツールを利用して、データに対して高度な処理、変換、分析を実行できます。しかし、その前に、まずは S3A コネクタを設定する必要があります。
S3A コネクタは、S3 互換ストレージ用の Hadoop DFS プロトコルが実装されたものです。S3A コネクタを使用すると、Hadoop エコシステムは FlashBlade などの S3 互換ストレージにデータを保存して処理することができます。S3A には長年の実績があり、特にパブリッククラウドでよく使用されています。S3A の設定例を以下に示します。
|
1 2 3 4 5 6 |
fs.s3a.endpoint=192.168.170.12 fs.s3a.access.key=YOUR_ACCESS_KEY fs.s3a.secret.key=YOUR_SECRET_KEY fs.s3a.connection.ssl.enabled=false |
これらを環境変数に追加します。Hadoop ディストリビューションの Spark および Zeppelin を使用している場合は、これらを core-site.xml ファイルに追加すると便利です。
AI 構築の鍵となるのが、AI モデルのトレーニングと検証の準備となるデータの調査とクレンジングです。Spark、Zeppelin、Jupyter は、これらの目的に適したツールです。次のセクションでは、これらのタスクについて解説します。
オープンソースとの連携と設定
S3A の設定が完了したら、Zeppelin UI を開いてノートブック「Dog Lover Analytics」を作成します。ブラウザからノートブックにアクセスし、ノートブックにコードブロックを書いてコードを実行します。コードは実行のためにバックエンド(Spark クラスタなど)へ送信されます。出力はノートブックに表示されます。このノートブックは次の図のようになっています。
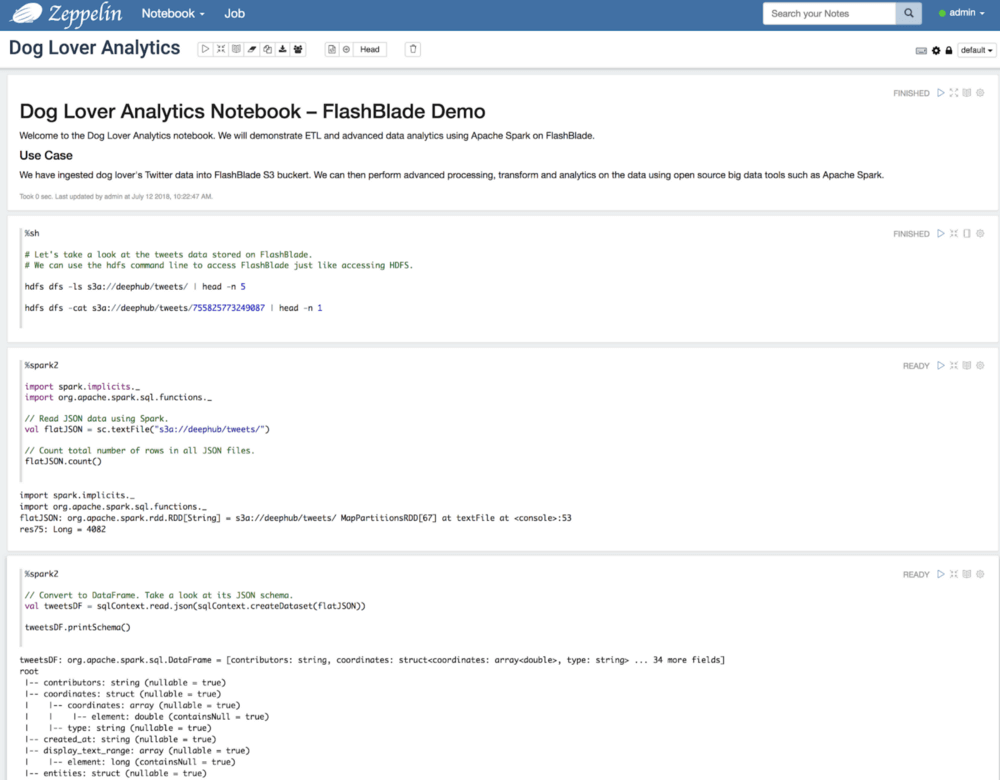
ノートブックで私が実際に行った内容をご紹介します。まず、FlashBlade S3 バケットにある生の JSON ファイルをリストします。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
%sh # Let’s take a look at the tweets data stored on FlashBlade. # We can use the hdfs command line to access FlashBlade just like accessing HDFS. hdfs dfs –ls s3a://deephub/tweets/ | head -n 5 Found 40 items –rw–rw–rw– 1 zeppelin zeppelin 819360 2018–07–06 16:23 s3a://deephub/tweets/755825773249087 –rw–rw–rw– 1 zeppelin zeppelin 640045 2018–07–06 16:23 s3a://deephub/tweets/755847797668277 –rw–rw–rw– 1 zeppelin zeppelin 750379 2018–07–06 16:23 s3a://deephub/tweets/755874821579546 –rw–rw–rw– 1 zeppelin zeppelin 778645 2018–07–06 16:23 s3a://deephub/tweets/755898847037685 |
次に、Spark で JSON データを読み取り、全てのファイルの行数を数えて合計を算出します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
%spark2 import spark.implicits._ import org.apache.spark.sql.functions._ // Read JSON data into Spark DataFrame using Spark. val tweetsDF = spark.read.json(“s3a://deephub/tweets/”) // Count total number of rows in all JSON files. tweetsDF.count() import spark.implicits._ import org.apache.spark.sql.functions._ tweetsDF: org.apache.spark.sql.DataFrame = [contributors: string, coordinates: struct<coordinates: array<double>, type: string> … 34 more fields] res15: Long = 4043 |
JSON スキーマは以下のようになります。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
// Take a look at its JSON schema. tweetsDF.printSchema() tweetsDF: org.apache.spark.sql.DataFrame = [contributors: string, coordinates: struct<coordinates: array<double>, type: string> … 34 more fields] root | – contributors: string (nullable = true) | – coordinates: struct (nullable = true) | | – coordinates: array (nullable = true) | | | – element: double (containsNull = true) | | – type: string (nullable = true) | – created_at: string (nullable = true) | – display_text_range: array (nullable = true) |
JSONスキーマには多くのフィールドがあります。そこから、最も影響力があるのは誰なのか、どのような内容のツイートをしているのかを確認したいと思います。Twitter データの上位 10 個を見てみましょう。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
tweetsDF.select($”user.id”, $”user.screen_name”, $”user.followers_count”, $”text”).orderBy($”user.followers_count”.desc).show(10) + – – – – – + – – – – – – – –+ – – – – – – – –+ – – – – – – – – – – + | id| screen_name|followers_count| text| + – – – – – + – – – – – – – –+ – – – – – – – –+ – – – – – – – – – – + | 15632759| ELLEUK| 1219160|Kylie Jenner Buil…| | 9609632| australian| 661614|Media Watch Dog: …| | 195516975| Joselyn_Dumas| 631885|RT @nii_sarpei: A…| | 15484198| georgegalloway| 291320|@lisalazuli @DecA…| |2909804893| DalmatianHd| 149545|RT @DalmatianHd: …| |2909804893| DalmatianHd| 149545|Meet Wiley: a swe…| |1347947466|Berti_and_Ernie| 147057|‘The world would …| | 54856746| jonfitchdotnet| 136636|My buddy’s new do…| | 244368081| TheMarkTwain| 130228|It‘s not the size…| | 115117283| CharitySANE| 106057|RT @Robinwindsor:…| + – – – – – + – – – – – – – –+ – – – – – – – –+ – – – – – – – – – – + only showing top 10 rows |
トップユーザーの @ELLEUK は、ELLE(エル) UK の公式 Twitter アカウントです。ファッション、セレブ情報を発信するメディアで、120 万人以上のフォロワーがいます。
ユーザー情報も重要です。ユーザーデータ専用のデータフレームを作成してみます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
val users = tweetsDF.select($”user.*”, $”text”) users.printSchema() users: org.apache.spark.sql.DataFrame = [contributors_enabled: boolean, created_at: string … 38 more fields] root | – contributors_enabled: boolean (nullable = true) | – created_at: string (nullable = true) | – default_profile: boolean (nullable = true) | – default_profile_image: boolean (nullable = true) | – description: string (nullable = true) | – favourites_count: long (nullable = true) | – follow_request_sent: string (nullable = true) | – followers_count: long (nullable = true) | – following: string (nullable = true) | – friends_count: long (nullable = true) … |
データフレームの一時的なビューを登録します。SQL を使用して同じクエリを実行し、その結果を Zeppelin で視覚化します。SQL は便利なのでお薦めです。
|
1 2 3 4 |
users.createOrReplaceTempView(“users”) select screen_name, followers_count from users order by followers_count desc limit 10 |

愛犬家のデータを後ほど詳しく分析したいので、FlashBlade に ORC ファイル形式でデータフレームを保存します。ORC は、ビッグデータワークロード用に最適化された列ファイル形式です。FlashBlade は強力な整合性を備えた S3 実装をサポートしているため、Spark は S3A を介してデータフレームを直接永続化できます。
|
1 2 3 4 5 |
import org.apache.spark.sql.hive.orc.OrcFileFormat users.write.format(“orc”).mode(“overwrite”).save(“s3a://deephub/twitter-users/”) |
次に、Hive を使用して FlashBlade に保存されているデータにアクセスします。これはユースケースの報告によく使用されます。Hive クライアントを開いてHive 内で外部テーブルを作成し、ロケーションとして FlashBlade のバケットを指定します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
create external table if not exists twitter_users( contributors_enabled boolean, created_at string, default_profile boolean, default_profile_image boolean, description string, favourites_count bigint, follow_request_sent string, followers_count bigint, `following` string, friends_count bigint, … ) stored as orc location “s3a://deephub/twitter-users/”; |
確認のためにサンプルクエリを実行します。
|
1 2 3 |
select screen_name, followers_count, text from twitter_users limit 10; |

数回のクリックと数行のコードを追加するだけで、FlashBlade 上でリアルタイムなデータ取得、ダッシュボード作成、詳細な分析を行うことができました。
次回予告
これで愛犬家のための AI は準備完了です!次回はいよいよニューラルネットワークモデルをトレーニングして展開し、画像から犬を検出します。お楽しみに!



