If your mission-critical Elasticsearch cluster experienced a failure today, how would you get your data back online? What if I told you that a Pure Storage® FlashBlade® could make your restores faster and easier to manage and simplify your recovery workflow?
Elasticsearch workload data is often overlooked as a part of common backup and restore strategies on-site. Often, the underlying files and data are backed up, and the plan is to reload Elasticsearch with the raw data again after bringing the system up.
What if there was a much faster way to do this—in minutes rather than hours? What if you could save hours of downtime and performance penalties? FlashBlade Object Storage can make this whole process easier and faster. But before we get to that, let’s look at a common failure event.
So, You’ve Encountered a Problem
Failure scenarios could come in the form of an event where the data storage is lost. This could be due to a storage failure. Or, the index is corrupted and needs to be rolled back due to corruption or hardware failure. If this happens, there are two common methods to recover the data.
Method 1: Reload Data from Existing Documents (Reload/Reingest)

The reload option is likely chosen as the default method (to not back up the system) since the data that is being searched in Elasticsearch usually exists in another repository in its original format as well. This typically means that recovery time isn’t a top concern. This option occurs when there’s a lack of backup strategy for an Elasticsearch system.
Reloading data is done using reingest tools like Filebeat for harvesting data and Logstash for transforming data. Reingesting the data can be slow since Filebeat is designed to monitor and receive incoming amounts of data constantly rather than a large amount all at once. Using multiple instances to reload means finding a way to partition data or check for duplicate records to avoid accidentally creating duplication. Logstash may be needed to transform the data into a format that is usable in Elasticsearch, which adds more processing time.
Loading data this way is not only slow but also the size in Elasticsearch may likely be different from the original data size each time due to differences in ingest system behavior when doing a reingest (differences such as how many instances of Filebeat were used, how Filebeat was configured, how Logstash was configured, etc.), as well as differences in the original data format (for example, was it a large single repository or was it initially added to Elasticsearch over time? How was it partitioned?). Elasticsearch itself also has an influence on the data sizing.
The size and speed of the raw data are configured by the Filebeat and Logstash setup. After receiving a portion of the raw data, Elasticsearch distributes the data between its data nodes, either creating a new index or updating an existing one (depending on options set for index sizing). The speed of this process is dependent on the Elasticsearch cluster size (larger is usually faster), data types/complexity, any extra transformations or schema mapping performed, and the number of ingesters feeding the data to Elasticsearch. The process of indexing the data (merging the data, in particular) is quite computationally expensive on the Elasticsearch cluster and running it at a rate to repopulate large amounts of data will likely affect other indices on the cluster that may be running queries at the same time (if they were unaffected by the outage).
The data restore process doesn’t apply to the underlying Elasticsearch instance or cluster. Unless an external tool or process is used, they aren’t backed up. A server failure could mean having to reload from an OS-level backup or perform a full rebuild before the data could be restored to the cluster.
Method 2: Snapshot and Restore

The snapshot and restore method involves using the Elasticsearch cluster itself to take a snapshot of the current indices to another storage device and allow data to be restored from that snapshot at another time. This can be done either manually or by scheduling it. The indices in the snapshot(s) taken may be reloaded individually or all at once with the cluster’s status.
As you probably already know, Elastic only recommends using snapshots and restores to back up and restore your data. This is the fastest method by a ridiculously wide margin. The data is already in the correct unit sizes and indexed, which keeps it from growing much larger once restored and minimizes the compute necessary to process raw data.
Once snapshots are configured, they can be set up on a schedule if needed, allowing for a point-in-time rollback in case of a data corruption error. This option brings flexibility to restores—you don’t have to start all changes over from scratch just to roll back a day.
However, there are drawbacks to the snapshot and restore method. Snapshots save the data but not the underlying Elasticsearch instance’s OS (which is also a problem with the reingest method). A server failure could mean having to reload from an OS-level backup or a rebuild before the data could be restored. The other requirement for snapshot storage is that it needs to have a plug-in available for it. At this time, there are plug-ins available for S3, Hadoop Distributed File System (HDFS), Azure, Google Cloud Storage, and OpenStack Swift.
Speed Up Restores with Pure FlashBlade
Pure Storage makes fast, dense storage to help speed up your business. Our FlashBlade line supports the S3 storage protocol, allowing Elasticsearch to store objects in a bucket locally. This makes the entire process much faster from both a storage and a setup perspective. With FlashBlade object storage, you can perform snapshots locally as you would to a cloud provider without having to build a local server cluster to host it. We tested this setup in our lab to understand how to configure it and also to see how the snapshot and restore method compares with the traditional reingest method.
Test Setup
We built a system consisting of three Elasticsearch master nodes, four Elasticsearch data nodes (each with 200GB of storage dedicated to data storage), one Kibana node, and four Filebeat nodes to test data ingestion. We then added a FlashBlade device as an S3 snapshot repository in Elasticsearch. For data, we generated 500GB of generic log data using a log generator and saved the data to a network file system (NFS) mount.
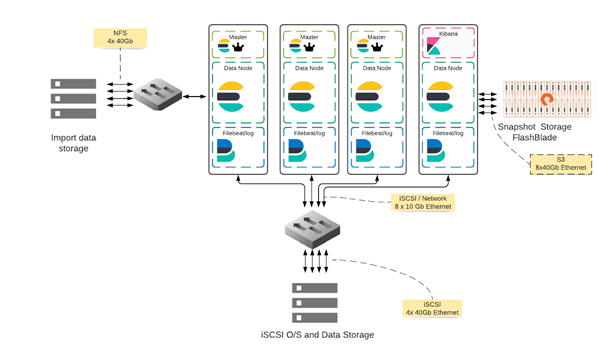
To test, we configured Filebeat to use two workers per node, with a bulk_max_size of 2048, using the close_eof option (to close files Filebeat had completed) and Elasticsearch with zero replicas after testing out different settings for speed of ingestion. We then timed the ingest of 500GB of data into Elasticsearch using four Filebeat nodes. When the ingest was complete, we took a snapshot of the S3 repository (using the Elasticsearch recommended 200MB/second max snapshot speed) and recorded the time to complete. We then deleted the indices created by the ingest process and did a full system state restore in Elasticsearch with a maximum restore rate of 1GB/second per node, recording the time to complete. Because the Elasticsearch data nodes have 200GB of storage, we tested only 500GB of data on the four-node cluster.

For the eight-node system, we added four more data nodes (eight in total) and four more Filebeat nodes (again, eight in total). To test this, we reran the four-node ingest and snapshot test, and then the restore tests with both 500GB and 1TB of data.
Results
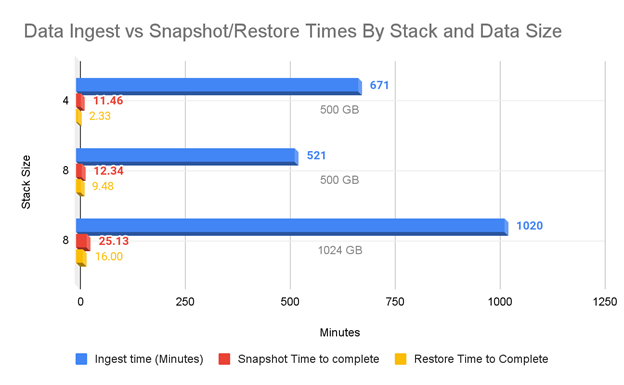
In the chart above, the stack size is how many Elasticsearch data nodes were used (as opposed to counting the three master nodes and one Kibana node), as well as how many Filebeat nodes we used for ingestion. The lower snapshot and restore times for 500GB on the four-stack cluster are due to the Elasticsearch data size after ingest. The four-stack cluster was 541GB and the eight-stack cluster generated 1153GB of data. The eight-stack cluster had more than two times the amount of data than the four-stack cluster.
You may also notice just how much faster it is to do a snapshot and restore than to ingest: roughly 24 times on a relatively modest eight-node cluster with 1TB of data combined. When looking purely at the restore times, it’s over 63 times faster. It would take 17 hours (1,020 minutes) to ingest with eight Filebeat nodes, compared to just 16 minutes for a restore. (The snapshot took over 25 minutes by itself but would likely not happen as part of the restore process.) If we were looking at linear scaling on 10TB of data, it would take a little over a week to ingest what a restore could accomplish in under three hours.
When thinking about your backup strategy for high-priority analytics systems, you’ll see much faster recovery times if you use snapshots and restores rather than ingestion of raw data. The difference in downtime costs means that it’s faster, and likely cheaper, to use snapshots. FlashBlade simplifies how you interact with Elasticsearch, as well as how fast you can restore. As your system scales up, FlashBlade will also scale up its performance.
Blazing-Fast Restore
Bounce back faster from an event failure with the industry’s most advanced all-flash storage solution.