



This article on optimizing deep learning workflows with fast S3 first appeared on Medium. It was replublished with the author’s credit and consent.
I know most data scientists do not care about storage, and they shouldn’t. However, having a fast S3 object storage in the system would definitely help optimize deep learning (DL) workflows. Let me explain why “storage actually matters in DL” in this blog post.
Distributed Training with Fast NFS
In my previous blog post, I explained why and how to scale from single node to distributed multi-node training, using Kubernetes, Horovod, and a fast NFS storage like FlashBlade® NFS. Below is the architecture we discussed in that blog post:
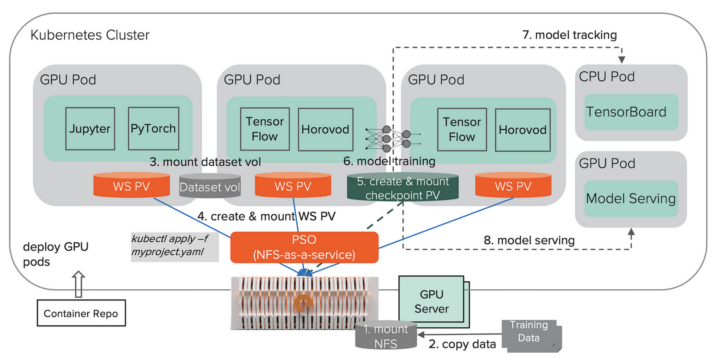
Deep learning with Kubernetes on FlashBlade NFS.
This works well as the first phase to onboard distributed training. While storage might be less appealing in a DL conversation, building a scalable DL system is like building a big house; you want to build a solid foundation before working on the roof. The foundation in a DL system is the infrastructure, including not just the GPU servers but also the storage and networks. In the above architecture, if we just focus on the NFS storage part, benefits it brings include:
- Allows training on large data sets that do not fit in a single host
- Allows teams to share expensive GPU hardware and data
- Makes it easier for machine learning engineers to aggregate logs, manage checkpoints, and export models
However, as the system scales and expands to support more machine learning workloads and operations, challenges arise. NFS is static to a host or pod, but DL workflows are very dynamic. Because all hosts/pods need to mount an NFS volume to access data in it, this could be challenging at scale:
- Data access control is at the host level. So there is risk of the data set being accidentally deleted from any host mounting that volume.
- Due to the above risk, the master copy of the data set is normally stored in a remote storage such as HDFS or S3. Copying data from HDFS or S3 to NFS could be slow.
- Difficult for reproducible model training, which requires centralized management for both the code and data.
- Difficult for elastic model serving. In large companies, model training and serving are normally run in different environments managed by different teams. Particularly, model serving systems might scale in and out frequently; NFS is simply not the best fit for that.
The solution here is to borrow the best practices of data engineering and DevOps into our DL workflow. One of those best practices I have seen a lot is the use of an object storage like S3 as the central data repository.
Optimizing DL Workflow with Fast S3
Prior to machine learning and deep learning, I spent 10+ years on big data (Hadoop and Spark) and DevOps (cloud, platform-as-a-service). One thing I learned from my experiences is that S3 object storage plays a critical role in these systems. This could also apply to large-scale DL systems.
How does a fast S3 object storage help optimize our DL workflow? The benefits come from using S3 as the central repository for both data and models. In the following revised architecture, instead of NFS, we use S3 on FlashBlade to store the training data sets, logs, and checkpoints.
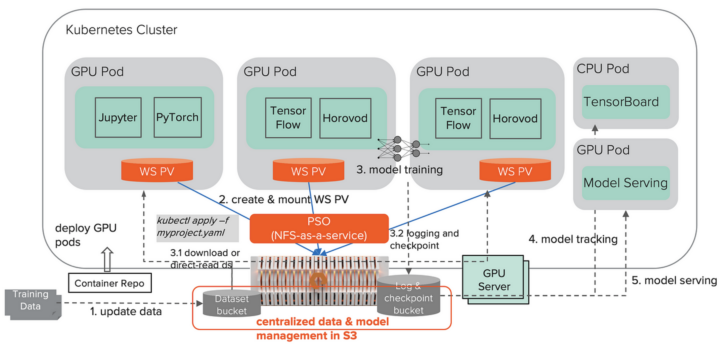
Optimizing DL workflow with fast S3.
We still use NFS but only for workspace volume, which stores temporary data only. We centralize training data and model management in the fast S3 object storage, which, unlike NFS, is managed on the storage side rather than each individual host and can be accessed from anywhere in the system. Fast S3 is an ideal fit for dynamic DL workflows.

Real-world Organizations Gaining ROI from AI
Using Data Sets in S3
Instead of putting the data set in NFS, we put it in an S3 bucket. This enables smooth integration with data engineering workflows. S3 is becoming the standard storage for many big data tools such as Apache Spark. Our data engineering team may use Spark to do the heavy ETL jobs and simply put the pre-processed output (e.g., Parquet files) in an S3 bucket. By using S3, we avoid an extra data copy between the data engineering and data science team. Take a look at my blog post on how to use Apache Spark with Kubernetes on S3. Once the pre-processing is done, output data will appear in S3 immediately. We can explore that data in JupyterLab using its S3 browser extension.
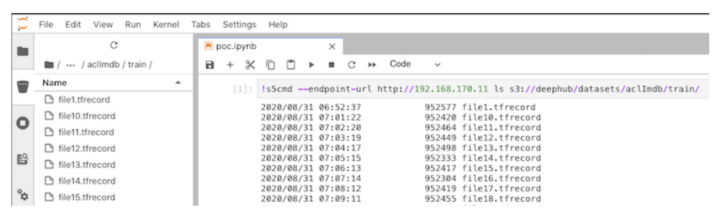
JupyterLab S3 browser.
Training jobs can then choose to download the data to its workspace NFS volume or directly read in S3 for training. Since S3 on FlashBlade is very fast, it is feasible to directly read the S3 data into the training iteration. This is especially powerful if the data set is too large to download. For example, instead of downloading 20TB of data, we can directly read from S3 in TensorFlow like this:
|
1 2 3 4 5 6 |
ds = tf.data.TFRecordDataset( s3_filepaths, num_parallel_reads=10, buffer_size=100000000) |
Compared to downloading the whole 20TB data sets, the above code uses minimum temporary storage and memory and can start immediately without waiting for download to complete. By using a fast S3 like FlashBlade S3 and tuning the number of parallel reads and buffer size, it is possible to reach comparable performance to that of reading from fast NFS.
Using S3 for Model Tracking and Serving
In the above architecture, we also use S3 for storing training logs, checkpoints, and models. This allows us to easily decouple model tracking and serving from training, which is essential for building a reproducible and scalable DL pipeline. The example below starts a TensorBoard pod pointing to logs stored in S3.
|
1 |
tensorboard —logdir s3://deephub/models/lstm-sentiment/logs –host 0.0.0.0 |
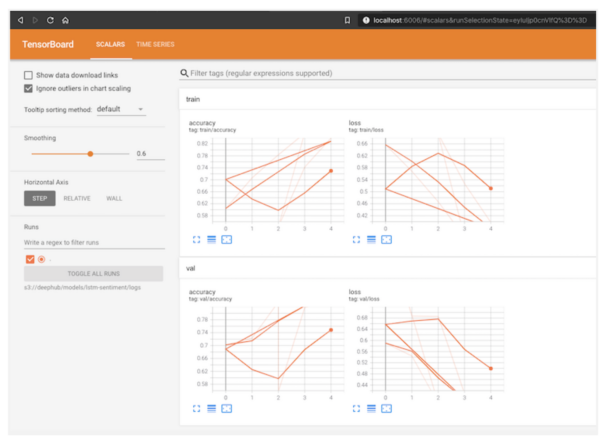
TensorBoard backed by S3.
We can also separately deploy an mlflow tracking server on Kubernetes and point it to the S3 bucket for advanced model tracking.
|
1 2 3 4 5 6 7 |
mlflow server \ —backend–store–uri postgresql://user:password@mypostgres:5432/mlflow \ —default–artifact–root s3://deephub/mlflow/ \ —host 0.0.0.0 |
mlflow tracking with S3 backend.
Similarly, model serving can also be backed by S3.
|
1 |
MODEL_BASE_PATH=s3://bucket/models tensorflow/serving |
Model serving is basically a web application that exposes the model as web APIs. Operating and scaling model serving is like a typical DevOps scenario. Having the origin model in S3, where all the serving pods can read and cache from, is like a common practice in DevOps to operate a stable and scalable web application.
Summary
Since all the important data, including the data sets, training logs, checkpoints, and models, is stored in S3, data and model management becomes much easier. Data in the S3 buckets is the golden record; it is centralized and protected. We can further enhance our data protection by using S3 replication and versioning. Advanced users may also build data governance, quality control, and model versioning on top of the S3 data.
To summarize, using S3 as the central data repository helps optimize DL workflows from the following points:
- Streamlined workflow. There is less storage operation involved. Data scientists can simply download or directly read data from S3 in their training code.
- Easy data and model management. We avoid data silos by putting the data in S3 as our golden record for data and models. Data protection, versioning, and tracking are easier. All of these would contribute to reproducible model training.
- Easy for elastic model serving. By decoupling model training, tracking, and serving, each stage in deep learning workflows can scale in and out independently, easily, and quickly.
Learn more about
Pure Storage Analytics and AI Solutions
Pure Storage FlashBlade Object Storage




