

Summary
Learn how to integrate and visualize Prometheus metrics with Grafana dashboards for Pure Storage FlashBlade™, with updates on enhanced monitoring capabilities, modern visualization tools, and expanded FlashBlade telemetry integration.


Grafana provides great visualization for Prometheus databases. Adding Grafana to a Kubernetes cluster can be done in three easy steps, which we will dig into further in this post:
- Deploy Granfana in your Kubernetes cluster.
- Create a dashboard in Grafana.
- Make your new dashboard persistent for all users in your cluster.
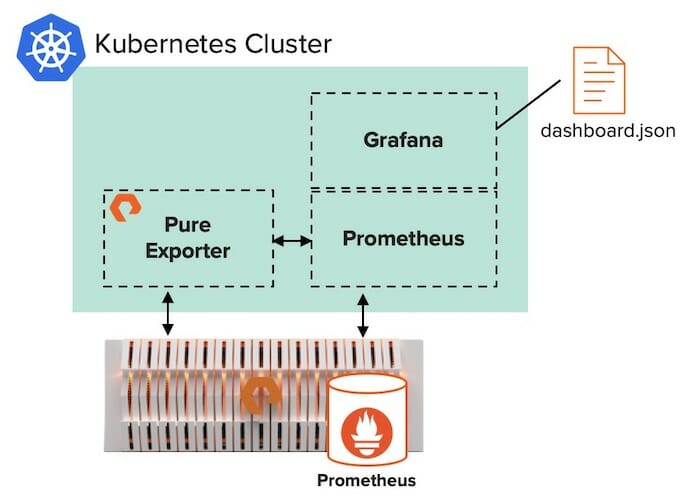
Step 1: Deploy Grafana in your Kubernetes Cluster
For this example deployment, we use Rancher as the cluster orchestration platform. Rancher simplifies management of Kubernetes clusters–especially for teams managing multiple clusters.
In order to use FlashBlade™ as the storage, we created a storage class named “pure-file” in our Kubernetes cluster. That storage class uses the Pure Service OrchestratorTM (PSO) to seamlessly auto-provision persistent volumes on FlashBlade as needed.
Persistent storage eliminates the possibility of destroying the data when the services are restarted. Using FlashBlade as persistent storage for Prometheus and Grafana can also provide data reduction. For example, our Grafana database is currently getting 6.4:1 data reduction.

For instructions on deploying a Rancher-based Kubernetes cluster using PSO on FlashBlade, please see our joint white paper with Rancher.
Then, it’s easy to add Prometheus to a Rancher-based Kubernetes cluster with these quick steps. During the Prometheus installation, Rancher allows users to deploy Grafana from the same window.
Step 2: Create a Dashboard in Grafana
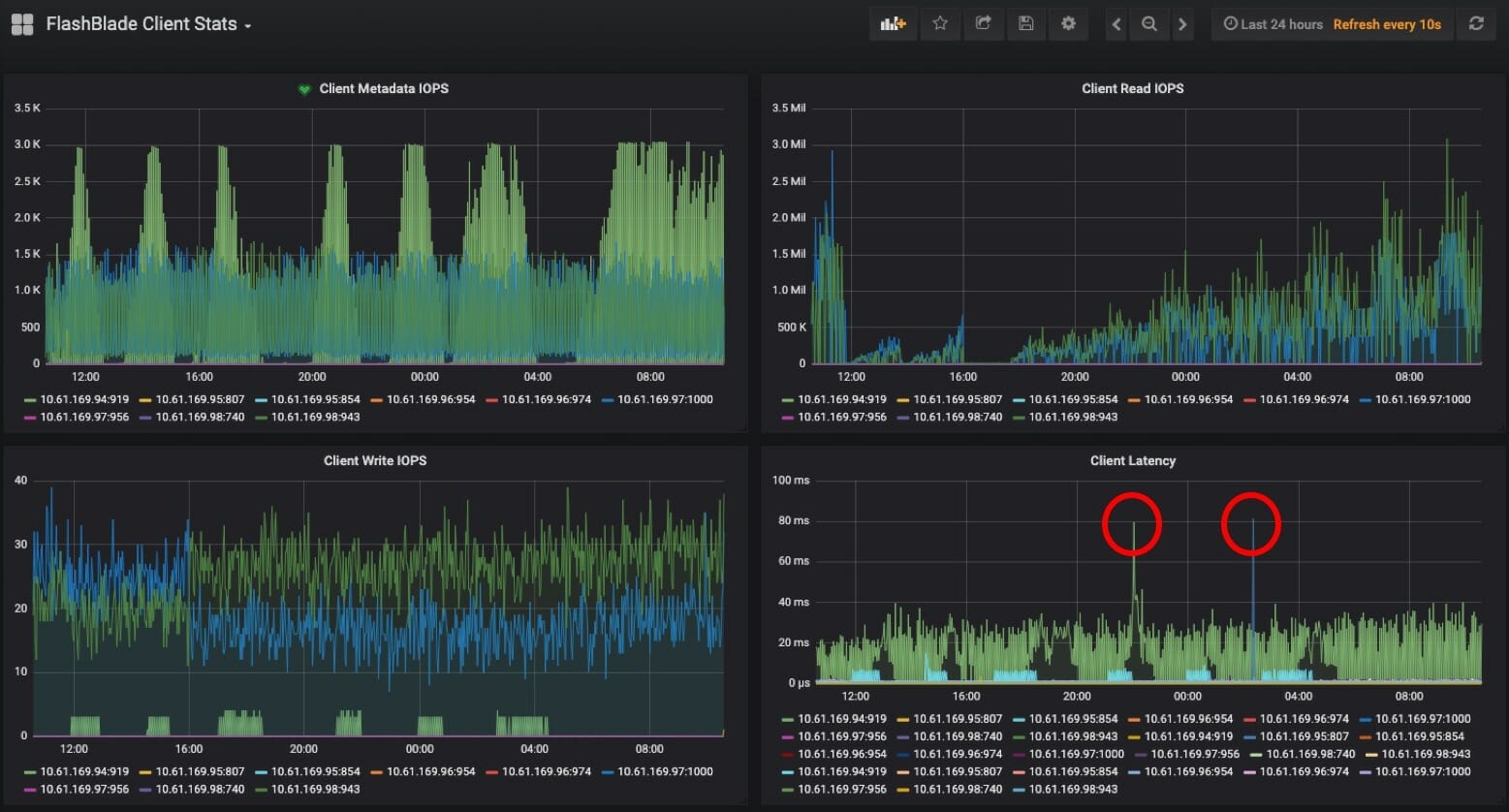
In the previous blog post, we discussed how to monitor per-client stats on a FlashBlade array. Now, we can create a “FlashBlade Client Stats” dashboard to visualize those metrics.
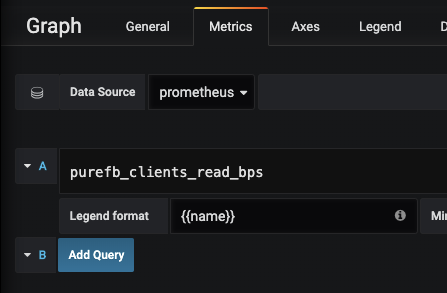
When building a new dashboard, after adding a new panel and selecting “Graph” type, using the new Prometheus metrics is as easy as specifying “Data Source: prometheus” and selecting the new metric.
Here’s an example of a finished dashboard we can use to visualize client statistics across our ML workloads:
Here are some helpful resources for learning more about creating Granfana dashboards and alerts:
- Grafana Getting Started Guide
- Hosted Graphite Grafana Dashboards
- IBM Cloud Configuring Alerts in Grafana
Step 3: Make your Dashboard Persistent
While users may have editing privileges in Grafana to create new dashboards, it’s necessary to move a new dashboard into the Kubernetes configuration in order to make it available for every Grafana user in the cluster.
Export the dashboard’s configuration file (JSON).

The “Share” menu will move to the sub-menu, where the “Export” tab provides the option to save the JSON configuration as a file.
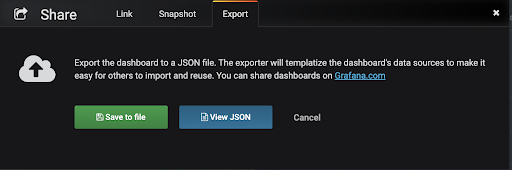
After exporting from Grafana, our client-stats-dashboard.json file looks something like this:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
“annotations”: {...}, … “panels”: [ {<<...panel...>>}, {<<...panel...>>}, {<<...panel...>>}, {<<...panel...>>} ] … “title”: “FlashBlade Client Stats”, “uid”: “wPsYtu-Wk”, “version”: 3 } |
The full JSON is much longer, but we just wanted to show the rough shape of it here because we’ll need to make a slight change to it before adding it to your cluster’s Grafana config map.
Since the Grafana config map saves information both for dashboards and for data sources, we need to add a prefix and suffix to our JSON to identify it as a dashboard.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 |
{ “dashboard”:{ “__inputs”:[ { “name”:“DS_PROMETHEUS”, “label”:“prometheus”, “description”:“”, “type”:“datasource”, “pluginId”:“prometheus”, “pluginName”:“Prometheus” } ], “__requires”:[ { “type”:“grafana”, “id”:“grafana”, “name”:“Grafana”, “version”:“5.0.0” }, { “type”:“panel”, “id”:“graph”, “name”:“Graph”, “version”:“5.0.0” }, { “type”:“datasource”, “id”:“prometheus”, “name”:“Prometheus”, “version”:“5.0.0” } ], “annotations”: {...}, … “panels”: [ {<<...panel...>>}, {<<...panel...>>}, {<<...panel...>>}, {<<...panel...>>} ] … “title”: “FlashBlade Client Stats”, “uid”: “wPsYtu-Wk”, “version”: 3 }, “inputs”: [ { “name”: “DS_PROMETHEUS”, “pluginId”: “prometheus”, “type”: “datasource”, “value”: “prometheus” } ], “overwrite”: true } |
Now we can add your dashboard’s JSON file to your cluster’s Grafana config map.
This client-stats-dashboard.json was added the configmap for Grafana in the Kubernetes cluster.
Because we deployed Prometheus via the app catalog, we have several auto-generated config maps for Prometheus, including one named “prometheus-grafana”.

Adding our new dashboard is as simple as adding a key-value entry.
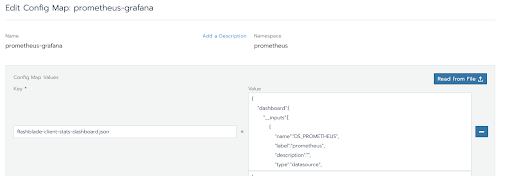
NOTE: because the config map describes both dashboards and datasources, the new dashboard’s key needs to end in “-dashboard.json”.
After we re-deploy the prometheus-grafana service, the “FlashBlade Client Stats” dashboard is now available for all cluster users who access our Grafana server.
Updates to Prometheus, Grafana, and FlashBlade™ Monitoring
Advancements in Prometheus, Grafana, and FlashBlade have introduced new features and capabilities that enhance monitoring, visualization, and operational efficiency. Below are some key updates and recommendations:
1. Enhanced Features in Grafana
- New Visualization Options: Modern versions of Grafana include advanced visualization options such as heatmaps, geomaps, and panel-specific overrides, allowing more granular insights into FlashBlade performance metrics.
- Alerting Enhancements: Grafana now supports unified alerting, enabling users to create, manage, and monitor alerts across multiple data sources in a centralized interface.
- Prometheus Native Integrations: Grafana’s updated Prometheus data source allows for more streamlined queries and visualization of metrics through improved templating and query builders.
- Learn More: Explore the latest Grafana updates for details on these features.
2. Prometheus Advancements
- Remote Write and Storage Enhancements: Prometheus now supports better integration with long-term storage systems, enabling retention of historical data for deeper analysis of FlashBlade metrics.
- New Exporters and Integrations: The ecosystem has grown with updated exporters, including Pure Storage-specific exporters, that allow seamless monitoring of FlashBlade-specific data.
- Improved Query Language (PromQL): New capabilities in PromQL make it easier to derive actionable insights from raw data.
- Learn More: Check out the Prometheus documentation for the latest updates.
3. FlashBlade Monitoring Enhancements
- Expanded Metrics with Pure1® Integration: Pure1® now provides predictive analytics and telemetry data down to granular levels, complementing Prometheus-based monitoring.
- Updated REST API Capabilities: FlashBlade REST APIs have expanded to include more operational metrics, making it easier to pull data into Prometheus for detailed monitoring.
- Sustainability Monitoring: FlashBlade now includes energy-efficiency metrics, helping organizations monitor and reduce their carbon footprint.
- Learn More: Visit the Pure Storage FlashBlade page for more details.
4. Best Practices for Modern Monitoring
- Hybrid Dashboards: Combine Grafana and Pure1® dashboards to gain a holistic view of real-time and historical data across FlashBlade environments.
- Leverage Advanced Plugins: Use the latest Grafana plugins to integrate additional Pure Storage data sources, ensuring comprehensive monitoring.
- Automated Alerting: Configure alerts in both Prometheus and Grafana to proactively address performance issues or unusual behaviors in FlashBlade systems.
By incorporating these updates and leveraging modern features, organizations can enhance their FlashBlade monitoring capabilities, ensuring operational efficiency, improved insights, and future-ready infrastructure.
Visualizing Prometheus Data with Grafana: Conclusion
Visualizing Prometheus data with Grafana provides powerful insights into the performance and health of FlashBlade systems. By leveraging the advanced features of modern Grafana and Prometheus updates, along with expanded telemetry capabilities from FlashBlade, organizations can create dynamic dashboards and actionable alerts to optimize their storage infrastructure. Whether monitoring real-time metrics or analyzing historical trends, this integration ensures that your FlashBlade systems operate efficiently and reliably, empowering you to make data-driven decisions with confidence.

White Paper, 7 pages
Learn What’s Helping CISOs Sleep Better at Night
And how you can too.



